第 4 章 - 行号工具(Line numbering tool)
本章内容包括:
- 从文件系统读取文件
- 通过函数参数对高阶函数的行为进行参数化
- 使用代数数据结构来编码可选项
- 将代码打包为可执行程序
在上一章中,我们为一个可以对文件内容进行行号编号的工具打下了基础。我们已经学会了如何从用户那里读取参数。因此,现在可以开始考虑如何从文件中读取数据,以及如何获取文件内容中的各个行。
本章将从“读取文件并转换内容”开始,然后编写一个通用函数,其控制流与数据流由作为参数传入的函数决定。接着,我们将学习如何使用代数数据结构来表达程序选项,并最终完成上一章中的工具。
4.1 文件读取与内容转换(Reading files and transforming their content)
为了完成这个任务,我们需要一个执行 IO 操作的动作。Haskell 提供了两个最基本的文件操作函数:
readFile :: FilePath -> IO String
writeFile :: FilePath -> String -> IO ()
顾名思义,readFile 从文件中读取内容,并将整个文件内容作为一个字符串返回;而 writeFile 接收一个字符串并将其写入到指定文件中,如果文件不存在则会自动创建。
这里我们又一次看到使用类型同义词(如 FilePath)的意义。仅从类型名就能明确知道参数的含义。如果直接使用 String 类型,这一点就不太明显。仅通过类型声明,我们就能推断出这些函数的大致用途。
接下来我们要使用 readFile 来构建一个能返回文件行列表的动作。为此,需要将文件内容按换行符 \n 进行分割。幸运的是,Haskell 为我们提供了一个现成的函数 lines,它正好可以做到这一点:
ghci> :t lines
lines :: String -> [String]
ghci> lines "Hello\nWorld\n"
["Hello","World"]
如你所见,lines 会把字符串按行分割,并自动去掉换行符。它还有一个反函数 unlines,几乎执行相反的操作:
ghci> :t unlines
unlines :: [String] -> String
ghci> unlines ["Hello", "World"]
"Hello\nWorld\n"
ghci> unlines (lines "Hello\nWorld")
"Hello\nWorld\n"
unlines 会在每个字符串后都加上一个换行符;而 lines 则会忽略输入字符串末尾是否缺少换行符。
除了这两个函数之外,还有 words 与 unwords,它们可以按空格分割(或重新拼接)字符串。所有这些函数都在 Data.String 模块中定义;但我们不需要显式导入,因为它们已通过 Prelude 导出,而 Prelude 是每个 Haskell 程序默认导入的模块。
💡 注意:
Prelude会重新导出来自不同模块的重要函数。例如,readFile和writeFile实际上最初定义于System.IO模块。由于Prelude默认导入,我们不必显式引入System.IO。当然,也可以通过编译器标志或 pragma 禁用Prelude的自动导入,但通常没有必要。
现在,我们可以编写一个动作,使用 readFile 和 lines 来读取文件的每一行。我们先读取文件内容,然后将其传给 lines 函数并返回结果。如下所示:
-- 代码清单 4.1:读取文件行的动作
readLines :: FilePath -> IO [String]
readLines filePath = do
contents <- readFile filePath -- #1 读取指定路径下的整个文件内容
return (lines contents) -- #2 将文件内容按换行符分割为行列表
需要注意的是,如果文件不存在,此操作会抛出异常。这对我们来说没问题,因为错误信息足以提示用户出了什么问题,我们不需要额外处理这种错误。
在项目目录下创建一个名为 testFile.txt 的文件,并写入以下内容:
Hello
dear
reader!
然后启动 REPL(使用 stack repl),执行我们的动作:
ghci> readLines "testFile.txt"
["Hello","dear","reader!"]
很好!现在我们就可以开始为这些行添加行号了!
4.1.1 编写纯库(Writing a pure library)
现在我们可以把注意力转向项目中的 Lib 模块。由于给行编号的代码本身相当通用,因此理应保存在库模块中。在前面,我们已经处理了程序中的许多不纯(impure)部分,现在可以专注于编写纯代码(pure code)了——这部分逻辑应该更容易理解。
首先,让我们看看希望支持哪些功能:我们希望能够对每一行进行编号,或仅对满足某个条件(谓词)的行编号,例如行非空或包含某个子字符串。因此,我们需要一个函数,能够为行生成对应的行号映射。此外,我们还希望支持不同格式的行号显示,例如左对齐或右对齐。为此,在进行格式化之前,我们必须先收集所有行号,以计算所需的填充长度。
我们先思考如何用数据类型表示这种“从行号到行内容”的映射。我们知道必须支持把任意数量的数字映射到行内容上。同时,映射的顺序也很重要,因为我们要知道打印时的顺序。列表(List)几乎能满足所有需求——它可以有任意长度,且顺序固定。但问题是:如何在列表中表示一个映射?答案就是关联列表(associative list)。关联列表的每个元素代表一个键值映射。而最简单的键值组合方式就是二元组(tuple),它可以把两个不同类型的值放在一起。
因此,一个可能的类型定义如下:
type NumberedLines = [(Int, String)]
这样,我们就能用它来表示行号与行内容的对应关系。
💡 注意 关联列表非常灵活,可以用来构建多种映射结构。 不过,它们的算法在运行时复杂度上通常比较高,因为大多数情况下查找键都需要遍历整个列表。 但如果性能不是主要关注点,关联列表依然是一种非常方便的数据结构。
举个例子:
[(1, "First Line"), (2, "Second Line"), (3, "Third Line")]
不过,这种表示方式并不能完全满足我们的需求。因为我们希望能选择性地给某些行编号——也就是说,有些行可能没有行号。因此,我们需要一种能表达“某行可能没有编号”的类型。幸运的是,我们之前已经见过可以表示“缺失值”的类型:Maybe。我们可以这样定义:
type NumberedLine = (Maybe Int, String)
type NumberedLines = [NumberedLine]
这样,一个行元素包含一个可选的行号和行内容的字符串。而所有的编号行就是这些映射组成的列表。
💡 注意 在这里我们看到,
Maybe不仅能用于捕获错误,也能用于表达“可选值”。 许多其他语言也有类似 HaskellMaybe的类型,通常被称为Option或类似的名字。
既然我们已经有了表示行号的类型,那么就可以考虑需要构造哪些函数了。我们需要一个函数来生成行号;但它还必须能够跳过某些行的编号。此外,我们还需要一个选项,用来控制何时递增行号——因为“计数行数”和“编号行”是两个不同的概念。例如,我们可能想跳过空行,但是否仍然计数这些空行?如图 4.1 所示,这两种方式的区别很明显——理想情况下,这应该由用户自行配置。
图 4.1:不同方式的空行编号)
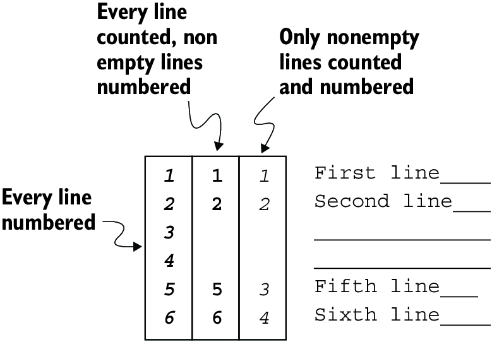
正如我们在上一章学到的,高阶函数(higher-order functions)可以接收其他函数作为参数,这些参数函数能够有效地参数化其行为。 由于我们需要为“何时忽略行”和“何时编号”定义复杂规则,因此这正是编写高阶函数的好机会—— 这个函数可以接收两个谓词参数,分别控制“何时递增编号”和“何时给行编号”。
4.1.2 隐藏辅助参数(Hiding auxiliary arguments)
我们先从最简单的情况开始——编写一个函数,给每一行编号,不带任何条件。然后我们再逐步改进。先考虑类型:我们接收一个字符串列表(即各行文本)作为输入,需要生成前面定义的 NumberedLines。那行号计数器该怎么处理?我们要不要把它作为参数暴露出去?理想情况下不应该——因为我们希望从 1 开始编号。但如果我们想递归地实现这个函数,就必须有办法在递归调用中传递“递增后的计数器”。我们需要的是一个在外部函数内部定义的隐藏函数。可以使用 let 绑定来实现,如下图所示:
代码清单 4.2:包含局部函数定义的函数结构
numberAllLines :: [String] -> NumberedLines
numberAllLines lines =
let go :: Int -> [String] -> NumberedLines -- #1 使用 `let` 定义了一个局部函数
go counter lines = ...
in go 1 lines -- #2 调用局部函数
这与我们之前看到的 let 稍有不同。那是因为 let 在与 do 表达式配合使用时的语义不一样。在纯函数中,let 用来创建局部定义(这些定义可以互相引用),并通过 in 关键字将它们引入作用域,如图 4.2 所示。定义的顺序无关紧要。
图 4.2:
let绑定的语法结构
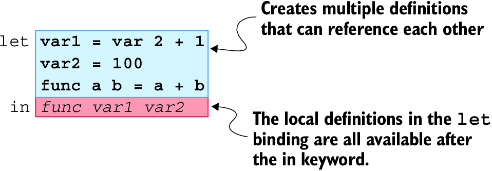
因此,我们可以使用 let 创建一个不同类型签名的内部函数,然后在主函数中调用它。内部函数可以拥有比外部函数更多(或完全不同)的参数。这样,我们就能在递归函数中隐藏默认参数,比如下面示例中的计数器变量。
💡 注意 当为这种局部函数起名时,通常使用
go或aux(即 auxiliary 的缩写)。这表示该函数只是某个更大定义的一部分。
现在我们可以递归地增加计数器了。每次递归调用都会创建一个新的行号映射,并在行号加一后继续处理下一行。最终结果是通过连接新生成的映射((Maybe Int, String) 元组)与递归调用结果构成的列表。
代码清单 4.3:给每一行编号的函数
numberAllLines :: [String] -> NumberedLines
numberAllLines lines =
let go :: Int -> [String] -> NumberedLines -- #1 局部函数的类型签名
go _ [] = [] -- #2 当输入为空列表时返回空列表(递归终止条件)
go counter (x : xs) = (Just counter, x) : go (counter + 1) xs -- #3为当前行创建新的编号映射,并递归处理剩余行
in go 1 lines -- #4 调用辅助函数,并传入初始行号 1
在这个例子中,go 函数在第一个模式中使用了通配符 _ 作为参数。为什么?因为在这一分支(空列表情况)中不需要使用计数器变量,
因此我们不必为它命名。在不需要某个参数时使用 _ 是一个良好的习惯。
练习:行与单词(Lines and Words)
lines、unlines、words 和 unwords 是处理字符串时非常有用的函数。请尝试使用递归定义自行实现这些函数!记住,String 其实就是 Char 的列表,因此你可以对其进行模式匹配。同时,可以使用 let 在函数中引入带有额外参数的内部定义,并配合守卫(guards)来实现这些功能。现在我们已经有了一个可以给传入的所有行编号的函数。我们可以在 GHCi 中测试它:
ghci> numberAllLines ["Hello", "", "World"]
[(Just 1,"Hello"),(Just 2,""),(Just 3,"World")]
4.2 高阶函数中的参数化行为(Parametrized behavior in higher-order functions)
接下来我们来解决检测空行的问题。我们希望给用户提供一个选项:是否为这些空行编号。但这意味着我们首先要能检测出空行。当然,如果一行是空的(不包含任何字符),我们可以认为它是空行。然而,如果这一行只包含控制字符(无法打印)或空白字符呢?在这种情况下,我们也应该把它视为空行。我们需要的是一个谓词函数,用于判断一个字符串是否应被视为空。换句话说,它是一个返回布尔值的函数。要检测字符串中是否包含控制字符或空白字符,我们可以使用 Data.Char 模块中的一些实用函数:
isPrint判断字符是否可打印;isSeparator判断字符是否为空白符或其他 Unicode 分隔符。
ghci> import Data.Char
ghci> isPrint 'a'
True
ghci> isPrint '\n'
False
ghci> isSeparator ' '
True
ghci> isSeparator 'a'
False
我们可以利用这些函数构建一个谓词,用来检测字符串是否为空或仅由不可打印字符组成。为此,可以使用 all 函数,它用于检查列表中所有元素是否满足给定谓词:
ghci> all (\x -> x == 1) [1,1,1 :: Int]
True
ghci> all (\x -> x == 1) [1,1,2 :: Int]
False
我们可以据此编写一个函数:若字符串为空,或者仅包含不可打印字符或空白符,则返回 True。该函数如下所示:
代码清单 4.4:检测字符串中是否至少包含一个可打印字符的谓词
isEmpty :: String -> Bool
isEmpty str =
null str -- #1
|| all (\s -> not (isPrint s) || isSeparator s) str -- #2
- #1 若字符串为空,则返回
True; - #2 若字符串仅包含不可打印字符或分隔符,也返回
True。
现在我们可以测试这个函数:
ghci> isEmpty "Test"
False
ghci> isEmpty " "
True
ghci> isEmpty "\n "
True
ghci> isEmpty "A "
False
此外,我们还可以定义它的对偶函数,用于检查字符串是否非空:
isNotEmpty :: String -> Bool
isNotEmpty str = not (isEmpty str)
现在,我们可以开始修改行号函数。由于我们想基于字符串的谓词来控制流程,因此我们已经知道新函数参数的类型应为 String -> Bool。我们需要两个谓词:
- 一个用于判断是否应递增计数器;
- 一个用于判断是否应为某行编号。
新的函数签名如下:
numberLines :: (String -> Bool) -> (String -> Bool) -> [String] -> NumberedLines
numberLines shouldIncr shouldNumber text = ...
我们将函数改名为 numberLines,因为它现在是一个通用的行编号函数。在函数定义中,我们可以用 if-then-else 语句在 let 绑定里控制是为某行编号、是否递增计数器,或两者都不做。代码如下:
代码清单 4.5:通用的高阶行编号函数
numberLines :: (String -> Bool) -> (String -> Bool) -> [String] -> NumberedLines
numberLines shouldIncr shouldNumber text =
let go :: Int -> [String] -> NumberedLines -- #1
go _ [] = [] -- #2
go counter (x : xs) =
let mNumbering = if shouldNumber x then Just counter else Nothing -- #3
newCounter = if shouldIncr x then counter + 1 else counter -- #4
in (mNumbering, x) : go newCounter xs -- #5
in go 1 text -- #6
- #1 局部定义的函数类型签名;
- #2 当输入列表为空时返回空列表,即递归终止条件;
- #3 若谓词判断应编号,则为当前行赋予编号;
- #4 若谓词判断应计数,则递增计数器;
- #5 使用新变量递归调用;
- #6 以固定初始值
1调用辅助函数。
通过这些谓词,我们可以控制计数与编号行为。由此,我们能基于该函数构建不同变体。
4.2.1 部分函数应用(Partial Function Application)
为了定义一个“给所有行编号”的函数,我们需要两个始终返回 True 的函数,因为我们总是想计数并编号。我们可以这样写:
(\_ -> True)
这个函数会忽略输入并始终返回 True。但我们还可以更一般地写出一个函数,它始终返回某个常量,并忽略第二个参数:
const :: a -> b -> a
const x = (\_ -> x)
现在,表达式 const True 与之前的 (\_ -> True) 等价。注意它的类型签名:我们使用了两个自由类型变量。通过让第二个参数的类型为 b,我们说明它可以与第一个参数类型不同。我们可以把这个函数改写成更常见的形式:
const :: a -> b -> a
const x _ = x
这样,我们得到一个可以生成常量一元函数的通用函数。实际上,这个函数在 Haskell 中已经存在!于是我们可以用它来定义 numberAllLines:
numberAllLines :: [String] -> NumberedLines
numberAllLines text = numberLines (const True) (const True) text
看起来有些奇怪:const True 明明是一个二元函数,为什么只传了一个参数?这就是部分函数应用(partial application)的威力。在 Haskell(以及许多其他函数式语言)中,你不必一次性提供函数的所有参数;若缺少参数,表达式会计算为另一个仍然“等待”缺失参数的函数。例如,当我们有表达式 (\x -> f x) 时,可以执行 η(eta)化简:它会被简化为 f。这种化简可以重复应用于多参数函数,使得我们能写出极为简洁的定义。让我们看看 const 的例子: const True 等价于 (\_ -> True),其类型由 const :: a -> b -> a 推得:第一个参数是 True,所以 a 的类型是 Bool,最终类型为:
b -> Bool
也就是说,它接受任意类型的参数并返回 Bool,这完全合理,因为参数被忽略了。
我们甚至可以对 numberAllLines 再进行一次 η 化简:
numberAllLines :: [String] -> NumberedLines
numberAllLines = numberLines (const True) (const True)
从类型上看也完全吻合:numberLines 的类型是(String -> Bool) -> (String -> Bool) -> [String] -> NumberedLines,
而 const True 的类型是 b -> Bool。将 b 替换为 String 后,结果类型正好是 [String] -> NumberedLines。
💡 提示: η 化简是一种让函数定义更简洁的好方法。 它在 Haskell 代码中极为常见。虽然不是必须使用,但熟悉它能帮助你更轻松地阅读他人的代码。
我们可以测试 numberAllLines 是否正常工作:
numberAllLines ["Hello", "", "World", "!"]
[(Just 1,"Hello"),(Just 2,""),(Just 3,"World"),(Just 4,"!")]
确实,所有行都被编号了。但我们并非为了这种简单情况才泛化函数——让我们来忽略一些行吧。
练习:使用 η 化简
上一章的项目实现时没有使用 η 化简,以便语法更易理解。 现在你已经了解了这种化简,请查看项目源码,看看哪些地方可以进行 η 化简。
接下来我们编写一个函数:它对每一行都递增计数器,但不为空行编号。我们可以继续使用 numberLines 的两个谓词参数:第一个应始终返回 True(总是计数),第二个则应是我们之前定义的“非空行”谓词。
numberNonEmptyLines :: [String] -> NumberedLines
numberNonEmptyLines = numberLines (const True) isNotEmpty
同样,我们使用 η 化简避免写出 [String] 参数。测试如下:
ghci> numberNonEmptyLines ["Hello", "", "World", "!"]
[(Just 1,"Hello"),(Nothing,""),(Just 3,"World"),(Just 4,"!")]
我们始终递增计数器,但不为空行编号。再写一个版本:既不为空行编号,也不在空行上递增计数器。
numberAndIncrementNonEmptyLines :: [String] -> NumberedLines
numberAndIncrementNonEmptyLines = numberLines isNotEmpty isNotEmpty
测试结果:
ghci> numberAndIncrementNonEmptyLines ["Hello", "", "World", "!"]
[(Just 1,"Hello"),(Nothing,""),(Just 2,"World"),(Just 3,"!")]
至此,我们从通用定义(代码清单 4.5)派生出了三个功能差异明显的函数,概述如下:
代码清单 4.6:根据不同条件为行编号的三种变体
numberAllLines :: [String] -> NumberedLines
numberAllLines = numberLines (const True) (const True) -- #1
numberNonEmptyLines :: [String] -> NumberedLines
numberNonEmptyLines = numberLines (const True) isNotEmpty -- #2
numberAndIncrementNonEmptyLines :: [String] -> NumberedLines
numberAndIncrementNonEmptyLines = numberLines isNotEmpty isNotEmpty -- #3
- #1 为每一行编号;
- #2 仅为非空行编号,但空行也会计数;
- #3 仅为非空行编号,空行既不编号也不计数。
通过这些定义,我们可以清楚地看到,只需编写简单的布尔谓词,就能灵活地控制何时为行编号、何时递增行号。
4.3 用代数数据结构表示各种可能性(Algebraic data structures as an encoding of possibilities)
现在我们已经有了一个用于给行编号的函数,接下来只需要把它们打印出来。我们最后要解决的一个问题是——如何将行号进行左对齐或右对齐填充。我们希望这里同样采用通用的方式。既然我们已经知道需要在左边或右边填充空格,那我们可以想象写一个参数化函数,它可以根据某个“选项”来决定是左填充还是右填充。但问题是:这个“选项”该长什么样?
4.3.1 求和类型或标记联合(Sum types or tagged unions)
为此,我们回顾一下前面在讨论 Maybe 类型时看到的 data 关键字。我们了解到它可以用来定义新的数据类型及其构造器。这些构造器的一个重要特性是:它们可以被模式匹配。这让我们可以很方便地用这种数据类型来创建一个简单的和类型(sum type),从而表示我们想表达的不同“变体”。一个和类型(有时称为标记联合)是一种数据类型,它由有限个固定类型的构造器(constructor)*组成,但在任意时刻只有其中*一个是有效的。这些构造器带有名字(这也是“tagged union”中“tag”一词的由来)。为了表示字符串填充的不同方向,我们可以让这些“标签”表示左填充或右填充。
代码清单 4.7:区分左填充与右填充的简单类型
data PadMode = PadLeft | PadRight
这个类型如代码清单 4.7 所示。你可以这样理解它:PadMode 要么是 PadLeft,要么是 PadRight。我们的 pad 函数可以对这个类型进行模式匹配(pattern match),从而根据不同的值决定字符串的填充方向。就像使用 type 关键字创建的类型一样,使用 data 关键字创建的类型也必须被添加到模块的导出列表中。而由于这个类型带有两个构造器(PadLeft 和 PadRight),我们也需要将它们一并导出。我们可以通过在导出列表中添加 PadMode (..) 来实现这一点。
那么,**我们该如何填充字符串呢?**如果一个字符串的长度小于指定的目标长度,就需要在它的两侧添加空格(当然,具体是左侧还是右侧取决于 PadMode),以使最终字符串的长度等于目标长度。为此,我们可以使用 replicate 函数。
ghci> :t replicate
replicate :: Int -> a -> [a]
ghci> replicate 10 ' '
" "
这个函数接受一个整数和任意类型的值,返回一个列表,其中该值会被重复指定的次数。那如果参数是负数呢?
ghci> replicate (-1) 'a'
""
结果是一个空列表。也就是说,replicate 的实现很巧妙:显然,负长度的列表是不存在的,所以它直接返回空列表。这意味着我们可以放心地用它来计算字符串的填充,无论是在左边还是右边。
计算公式很简单:
replicate (<desired length> - <actual length>) ' '
replicate (目标长度 - 实际长度) ' '
于是,我们可以用 let 绑定快速写出一个函数:它计算目标长度与实际长度的差值,然后生成所需的填充:
pad :: Int -> String -> String
pad n str =
let diff = n - length str -- #1 计算目标长度与实际长度的差值
padding = replicate diff ' ' -- #2 计算所需的填充空格
in ...
但是,我们还没考虑 PadMode!这个参数应该放在哪?一个合理的答案是:放在第一个参数位置。为什么?——想想部分函数应用(partial function application)。如果我们把模式参数放在最前面,就可以直接传入模式(例如 PadLeft),然后得到一个“带方向的”填充函数!
接下来的问题是:**模式匹配该放在哪?**目前我们只见过在函数参数里做模式匹配,但这次我们希望复用前面 let 定义的变量,而不是在每个分支中重复定义。为此,我们可以使用 case ... of 表达式,它的语法如下:
case <表达式1> of -- #1
<模式1> -> <表达式2> -- #2
<模式2> -> <表达式3> -- #3
...
- #1:开始匹配
<表达式1>。 - #2:若
<模式1>匹配成功,则结果是<表达式2>的值。 - #3:同理,若
<模式2>匹配成功,则取<表达式3>的值。
模式与我们之前使用的一样。我们现在可以用这种语法来匹配 PadMode,把它加入到 pad 函数中,使得函数可以根据模式切换填充方向。
代码清单 4.8:可左填充或右填充的通用函数
data PadMode = PadLeft | PadRight -- #1 定义左右填充模式
pad :: PadMode -> Int -> String -> String
pad mode n str =
let diff = n - length str -- #2 计算目标与实际长度的差值
padding = replicate diff ' ' -- #3 计算所需的填充空格
in case mode of -- #4 匹配模式参数
PadLeft -> padding ++ str -- #5 若为左填充
PadRight -> str ++ padding -- #6 若为右填充
现在,我们就得到了一个优雅的通用填充函数!将新函数添加到模块导出列表后,我们就可以在 GHCi 中试验:
ghci> pad PadLeft 10 "Pad me!"
" Pad me!"
ghci> pad PadRight 10 "Pad me!"
"Pad me! "
完美地实现了左右方向可选的填充逻辑。
4.3.2 不要重复自己(Don't repeat yourself)
现在我们可以再次利用部分函数应用从这个非常通用的函数派生出更具体的函数,如代码清单 4.9 所示。为什么这样写代码是一个好办法?首先,我们不用重复自己(DRY),在编程中这始终是个好目标。再者,设想我们想添加一个 PadCenter 模式,使字符串在左右两侧都进行填充以实现居中显示。那种情况下,我们只需扩展数据类型并在模式匹配中加入另一种分支。其他定义仍然可以复用。这能节省时间——不用一次又一次地重实现相同逻辑。尽管对于这个(相当简单的)例子看起来好像牵强,但在实现更复杂的函数时,这种做法确实能节省大量时间。还有一个引入模式参数(mode parameter)的好处。假设我们想构造一个使用 pad 函数的函数(这是我们想做的),但填充方式并非预先确定。如何将其参数化?当然,我们可以把执行填充的函数作为参数传入,但直接提供 Pad 模式要更清晰——从参数一眼就能看出其用途。
代码清单 4.9 基于通用填充函数的左右填充函数:
padLeft :: Int -> String -> String
padLeft = pad PadLeft -- #1
padRight :: Int -> String -> String
padRight = pad PadRight -- #2
- #1 从通用
pad函数生成一个执行左填充的函数。 - #2 从通用
pad函数生成一个执行右填充的函数。
现在我们可以对数字进行填充,剩下的就是把 NumberedLines 转换成可以打印的东西了!
练习:实现居中填充 我们讨论过如何扩展代码清单 4.8(数据类型与
pad函数)以创建居中填充,使输入字符串被填充后看起来位于结果字符串的中间。试试实现它!对整数做除法时,可以使用div函数。
4.3.3 zip 函数(The zip function)
为了将我们用 numberLines 函数生成的 NumberedLines 转换,我们需要另一个函数,把这个作为关联列表同义词的类型转换成更容易打印的形式——更具体地说,是一个字符串列表。为此,我们需要收集所有行号,找出最大长度,对行号做相应填充,然后把这些行号前置到每行文本前面。到这里都还好;但我们处理的是一个元组列表。我们需要把这个列表拆开以获得单独的行号,然后再把它们合并回去!
首先,回顾并(再次)把我们之前做的事情泛化!函数 numberLines 使用布尔谓词从简单字符串生成一个元组列表(类型为 (Maybe Int, String))。那么更一般地我们如何把两列列表合并成元组列表?Haskell 提供了一个很好的函数 zip,其类型为 [a] -> [b] -> [(a, b)]。正如拉链的两个牙齿在拉上时会配对,zip 把两个列表按位置合并为元组,并在遇到较短的那个列表结尾时停止。见图 4.3。看几个例子:
ghci> zip [1,2,3] ["Hello", "World", "!"] :: [(Int, String)]
[(1,"Hello"),(2,"World"),(3,"!")]
ghci> zip [1..10] ['a'..'z'] :: [(Int, Char)]
[(1,'a'),(2,'b'),(3,'c'),(4,'d'),(5,'e'),(6,'f'),(7,'g'),(8,'h'),(9,'i'),
(10,'j')]
ghci> zip [1..10] [] :: [(Int, Int)]
[]
图 4.3:副作用、动作与纯代码的相互作用
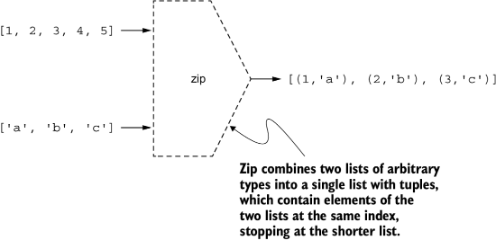
zip 有一个准逆操作 unzip。就像 zip 用来“合上”拉链,unzip 则把它“打开”:
ghci> unzip [(1,'a'), (2,'b'), (3,'c')] :: ([Int], String)
([1,2,3],"abc")
ghci> unzip (zip [1..5] ['a'..'c'] :: ([Int], String))
([1,2,3],"abc")
不过,从这个例子可以看到,unzip 并不是 zip 的真正逆函数,因为 zip 可能会舍弃较长列表中多余的元素(如果存在的话)。这些函数在处理关联列表时非常有用,因为它们提供了一种纯且安全的构造与拆解关联列表的方式。既然 NumberedLines 只是 [(Maybe Int, String)] 的同义词,它们就是拆解该类型的不错选择!虽然我们也可以重写一个专门的递归函数来拆解列表,但那样既容易出错,又会产生大量本质相同的函数。通过复用已有的基本函数,我们可以避免重复自己,并使函数定义更易读!
现在,要计算最大行号,我们需要取出所有行号,把它们转换为字符串(用 show),计算这些字符串的长度,并求最大值。这可以很简洁地用 maximum(Haskell 已提供)和 map 完成:
ghci> xs = [1..1000000] :: [Int]
ghci> maximum (map length (map show xs))
7
内层的 map 将数字列表转换成 String 列表;外层的 map 计算每个字符串的长度;maximum 返回外层 map 产生的列表的最大值。
用它来计算行号的最大长度后,我们就能生成用于填充行号的长度值。但如何将这些行号与实际行内容合并?zip 生成元组,而我们希望把两个元素合并成一个 String。这时需要一个通用版的 zip,允许我们指定如何合并两个元素——Haskell 也提供了这样的函数 zipWith。
ghci> :t zipWith
zipWith :: (a -> b -> c) -> [a] -> [b] -> [c]
ghci> zipWith (+) [1..10] [1..3] :: [Int]
[2,4,6]
ghci> zipWith (\x y -> (show x) ++ ": " ++ y) [1,2,3 :: Int]
["One", "Two", "Three"] :: [String]
["1: One","2: Two","3: Three"]
zipWith 是高阶函数的又一典型示例:我们只需传入一个函数就能完全改变它的行为!正如名字所示,它的行为类似于 zip,但会在合并元素时调用我们提供的函数,而不是构造元组。
练习:实现
zipWith像map一样,zip是任何 Haskell 开发者都应该熟练掌握的基本函数。为熟悉它,尝试使用递归实现zip,然后扩展实现zipWith。额外题:能否用zipWith来实现zip?
4.3.4 处理缺失值(Working with missing values)
最后一个需要注意的特殊点是:我们的行号类型不是普通的数值类型,而是 Maybe Int!因此,上述直接的技术无法直接使用。问题出在哪里?在对行号做 map 时,我们总得检查遇到的是 Just 还是 Nothing。为此,我们学到了 maybe 函数。有了它,我们可以很快地写出一个 map,将 [Maybe Int] 转换成 [String]:
ghci> ys = [Just 1, Just 2, Nothing, Just 4] :: [Maybe Int]
ghci> map (maybe "" show) ys
["1","2","","4"]
这里我们再次用了部分函数应用以简化定义。凭借这些工具函数,我们可以写出把 NumberedLines 转换为漂亮、可读字符串表示的函数,如下列出。
代码清单 4.10:将编号后的行转换为人类可读字符串的函数
prettyNumberedLines :: PadMode -> NumberedLines -> [String]
prettyNumberedLines mode lineNums =
let (numbers, text) = unzip lineNums -- #1
numberStrings = map (maybe "" show) numbers -- #2
maxLength = maximum (map length numberStrings) -- #3
paddedNumbers = map (pad mode maxLength) numberStrings-- #4
in zipWith (\n l -> n ++ " " ++ l) paddedNumbers text -- #5
- #1 将元组列表拆开为一对列表(行号列表与文本列表)。
- #2 把行号转换为字符串表示,并将
Nothing映射为空字符串。 - #3 计算所有行号字符串的最大长度。
- #4 将所有行号字符串按最大长度进行填充(使用给定的
mode)。 - #5 把填充好的行号与对应文本合并。
在这里,我们看到 let 绑定中的每个定义都是整体函数的一部分。每个被绑定的值像拼图块一样,直到最后一步拼合出整个结果。这也清楚地展示了完成该操作所需的各个计算步骤:拆开 NumberedLines、把行号转为字符串、找到最大长度、对行号进行填充,最后把它们组合成易读的字符串。编写处理较复杂问题的函数时,按这种方式把问题拆分为更小的子任务通常是个好主意——分治法与 let 语法配合得非常好!
注:前缀
pretty通常用于把数据转换为“可读形式”的函数。
这个函数也很好地展示了声明式编程风格:我们定义了一些中间结果,它们可以互相引用,只有最终表达式才产生整个函数的最终结果。这种风格不对这些定义计算的顺序做假设——这是我们在后续章节中会进一步探讨的内容。
4.3.5 使用 mapM 打印值列表(Printing a list of values with mapM)
现在,程序的几乎所有部分都已经处理完毕。最后要做的是把漂亮的编号行打印到屏幕上。我们需要一种方法,对漂亮行列表中的每个字符串执行打印。想到 map,它可以对列表中每个元素应用一个纯函数,但现在我们希望对每个元素执行一个动作(action)。普通的 map 无法直接执行动作——它只能构造出动作的列表而已。幸运的是,Haskell 提供了两个在动作上下文中与 map 等价的函数:mapM 与 mapM_。它们都接受一个产生动作的一元函数作为参数,并返回一个表示执行这些动作的总动作。传入的函数会对每个元素求值,而且这些动作会按顺序执行。把 putStrLn 与字符串列表结合使用正是它们的典型场景。那么应该选哪个?我们来看看示例:
ghci> mapM putStrLn ["Hello", "World", "!"]
Hello
World
!
[(),(),()]
ghci> mapM_ putStrLn ["Hello", "World", "!"]
Hello
World
!
这有点奇怪:mapM 打印了字符串后返回 [(),(),()](一个单位值列表),而 mapM_ 看起来似乎什么也不返回(实际上它返回 (),只是 GHCi 隐藏了显示)。两者的差异是什么?mapM 的行为就像 map:动作返回的值会替换原列表中的输入值,因此结果是这些动作返回值的列表。putStrLn 返回的是单位值 (),所以 mapM 会收集许多 () 到一个列表中返回。mapM_ 则是 mapM 的一个变体,用于那些我们不关心动作返回值的情况。因为单位值 () 不包含信息,我们可以直接丢弃它——这正是 mapM_ 所做的:忽略每个动作的输出,只返回单个 ()。
练习:实现单子版本的
map为简单起见,我们可以把两个map函数的类型假设为:
mapM :: (a -> IO b) -> [a] -> IO [b]
mapM_ :: (a -> IO b) -> [a] -> IO ()
尝试自己实现它们!先仔细分析纯 map 是如何构成的,然后查看本章开头的 interactiveLines 示例。你可以用相同思路实现 mapM 与 mapM_。
由于我们这里只关心把字符串列表打印出来,所以 mapM_ 正好满足我们的需求。用它打印编号行非常简单直接。
4.4 从库到可执行程序(From library to executable)
现在,我们可以把所有东西整合起来了!我们可以修改上一章的代码,让它能够读取用户指定文件中的行,对这些行进行编号,生成美观的编号版本,然后打印到屏幕上,如下示例所示。
代码清单 4.11 提供行编号工具基本功能的主程序
main :: IO ()
main = do
cliArgs <- getArgs -- #1
let mFilePath = parseArguments cliArgs -- #2
maybe
(printHelpText "Missing filename") -- #3
( \filePath -> do
fileLines <- readLines filePath -- #4
let numbered = numberAllLines fileLines -- #5
prettyNumbered = prettyNumberedLines
PadLeft numbered -- #6
mapM_ putStrLn prettyNumbered -- #7
)
mFilePath
说明: 1️⃣ 读取程序启动时传入的命令行参数 2️⃣ 解析文件名参数 3️⃣ 如果参数数量不正确,则输出帮助文本 4️⃣ 从文件中读取所有行 5️⃣ 对文件中的每一行进行编号 6️⃣ 生成带有行号的易读字符串表示 7️⃣ 将结果打印到屏幕上
把所有模块组合起来之后,我们终于可以测试程序了!让我们试着对一些行进行编号:
shell $ stack run -- testFile.txt
1 Lorem ipsum dolor sit amet, consectetur adipiscing elit. Maecenas a
2 mattis nisi, eleifend auctor erat. Vivamus nisl sapien, suscipit non
3 gravida sed, mattis a velit. Fusce non iaculis urna, a volutpat leo.
4 Ut non mauris vel massa tincidunt mattis. Sed eu viverra lectus.
5 Donec pulvinar justo quis condimentum suscipit. Donec vel odio eu
6 odio maximus consequat at at tellus. Ut placerat suscipit vulputate.
7 Donec eu eleifend massa, et aliquet ipsum.
8
9 Mauris eget massa a tellus tristique consequat. Nunc tempus sit amet
10 est sit amet malesuada. Curabitur ultrices in leo vitae tristique.
11 Suspendisse potenti. Nam dui risus, gravida eu scelerisque sit amet,
12 tincidunt id neque. In sit amet purus gravida, venenatis lectus sit
13 amet, gravida massa. In iaculis commodo massa, in viverra est mollis
14 et. Nunc vehicula felis a vestibulum egestas. Phasellus eu libero sed
15 odio facilisis feugiat id quis velit. Proin a ex dapibus, lacinia dui
16 at, vehicula ipsum.
在这里,我们可以清楚地看到 PadLeft 让行号右对齐了。
这个工具的功能与我们的预期大致一致。
接下来,我们清单上的最后一项任务是——添加更多选项。
4.4.1 命令行选项编码与解析(Encoding and parsing command line options)
最后,我们希望为程序添加更多选项。对于这个简单的应用程序,我们希望支持以下三个参数:
--reverse:反转行号顺序--skip-empty:跳过空行编号--left-align:行号左对齐
为了在程序中表示这些选项,我们可以使用代数数据类型(Algebraic Data Type)。如下所示(代码清单 4.12)。这里出现了一个新关键字 deriving,我们将在下一章详细介绍。目前你只需要知道,它允许我们为这个数据类型派生(derive)Eq 类型类,以便比较是否相等。
代码清单 4.12 表示行号程序选项的数据类型
data LineNumberOption
= ReverseNumbering -- #1
| SkipEmptyLines -- #2
| LeftAlign -- #3
deriving (Eq) -- #4
说明:
1️⃣ 表示 --reverse
2️⃣ 表示 --skip-empty
3️⃣ 表示 --left-align
4️⃣ 为此类型派生 Eq 类型类
基于这个数据类型,我们可以编写一个函数来将字符串解析为相应的构造器。这里我们再次使用 Maybe,以表示解析可能会失败。
代码清单 4.13 将字符串解析为选项类型的函数
lnOptionFromString :: String -> Maybe LineNumberOption
lnOptionFromString "--reverse" = Just ReverseNumbering -- #1
lnOptionFromString "--skip-empty" = Just SkipEmptyLines -- #1
lnOptionFromString "--left-align" = Just LeftAlign -- #1
lnOptionFromString _ = Nothing -- #2
说明:
1️⃣ 将匹配的字符串解析为对应构造器
2️⃣ 无法解析的字符串返回 Nothing
假设命令行参数的顺序是固定的:选项在前,文件名在后。这会让解析变得简单一些。我们可以使用 reverse 函数先反转参数列表。这样,文件名(原本最后一个)就成了反转后列表的第一个元素,这让我们可以方便地使用 x:xs 模式进行匹配。解析剩余的参数时,我们可以使用 Data.Maybe 模块中的 mapMaybe(类型为 (a -> Maybe b) -> [a] -> [b])来调用 lnOptionFromString。mapMaybe 会自动忽略所有 Nothing 值,也就是说无法解析的参数会被跳过。最终,我们返回一个 Maybe FilePath 和一个选项列表 [LineNumberOption]:
代码清单 4.14 解析命令行参数的函数
import Data.Maybe
...
parseArguments :: [String] -> (Maybe FilePath, [LineNumberOption])
parseArguments args = case reverse args of -- #1
[] -> (Nothing, []) -- #2
(filename : options) ->
( Just filename, -- #3
mapMaybe lnOptionFromString options -- #4
)
说明:
1️⃣ 对反转后的参数列表进行模式匹配
2️⃣ 参数为空时返回空结果
3️⃣ 如果存在文件名则返回 Just filename
4️⃣ 解析选项参数,忽略无效项
最后,我们可以将其整合进清单 4.11 的 main 函数中。在修改程序控制流之前,先停下来思考一下:程序的控制流主要由所使用的函数决定。当我们希望根据某些变量(如选项)来改变控制流时,在 Haskell 中,一个更优雅的做法是——直接切换函数。Haskell 中的函数是值,可以像其他值一样被传递、赋值。所以,与其把选项作为参数传入,不如根据选项动态选择不同的函数。
例如:
let numberFunction =
if SkipEmptyLines `elem` options -- #1
then numberNonEmptyLines -- #2
else numberAllLines -- #2
说明:
1️⃣ 检查 SkipEmptyLines 是否存在于选项列表中
2️⃣ 根据结果选择合适的函数
这里我们假设 options 的类型为 [LineNumberOption],它来自于上面 parseArguments 的结果。我们将函数赋值给变量 numberFunction,实质上是根据布尔表达式的结果改变函数定义。这让我们能够将选项逻辑优雅地融入主流程中。示例执行效果如下:
shell $ stack run -- --skip-empty --left-align --reverse testFile.txt
16 Lorem ipsum dolor sit amet, consectetur adipiscing elit. Maecenas a
15 mattis nisi, eleifend auctor erat. Vivamus nisl sapien, suscipit non
14 gravida sed, mattis a velit. Fusce non iaculis urna, a volutpat leo.
13 Ut non mauris vel massa tincidunt mattis. Sed eu viverra lectus.
12 Donec pulvinar justo quis condimentum suscipit. Donec vel odio eu
11 odio maximus consequat at at tellus. Ut placerat suscipit vulputate.
10 Donec eu eleifend massa, et aliquet ipsum.
8 Mauris eget massa a tellus tristique consequat. Nunc tempus sit amet
7 est sit amet malesuada. Curabitur ultrices in leo vitae tristique.
6 Suspendisse potenti. Nam dui risus, gravida eu scelerisque sit amet,
5 tincidunt id neque. In sit amet purus gravida, venenatis lectus sit
4 amet, gravida massa. In iaculis commodo massa, in viverra est mollis
3 et. Nunc vehicula felis a vestibulum egestas. Phasellus eu libero sed
2 odio facilisis feugiat id quis velit. Proin a ex dapibus, lacinia dui
1 at, vehicula ipsum.
4.4.2 项目概览(An overview of the project)
让我们回顾一下整个程序!项目的完整 Main 模块 如代码清单 4.15 所示,而 Lib 模块 如代码清单 4.17 所示。
代码清单 4.15:主模块中的头部、数据类型和工具函数
module Main (main) where
import Data.Maybe -- #1
import Lib -- #1
import System.Environment -- #1
data LineNumberOption -- #2
= ReverseNumbering
| SkipEmptyLines
| LeftAlign
deriving (Eq)
lnOptionFromString :: String -> Maybe LineNumberOption -- #3
lnOptionFromString "--reverse" = Just ReverseNumbering
lnOptionFromString "--skip-empty" = Just SkipEmptyLines
lnOptionFromString "--left-align" = Just LeftAlign
lnOptionFromString _ = Nothing
printHelpText :: String -> IO () -- #4
printHelpText msg = do
putStrLn (msg ++ "\n")
progName <- getProgName -- #5
putStrLn ("Usage: " ++ progName ++ " <options> <filename>")
putStrLn "\n"
putStrLn " Options:"
putStrLn " --reverse - Reverse the numbering"
putStrLn " --skip-empty - Skip numbering empty lines"
putStrLn " --left-align - Use left-aligned line numbers"
parseArguments :: [String] -> (Maybe FilePath, [LineNumberOption])
parseArguments args = case reverse args of -- #6
[] -> (Nothing, [])
(filename : options) ->
( Just filename,
mapMaybe lnOptionFromString options
)
说明:
- 导入程序定义所需的模块。
- 定义一个数据类型,表示命令行参数选项。
- 定义一个函数,用于解析单个命令行参数。
- 定义一个函数,用于为用户打印帮助文本。
- 返回程序运行时的名称。
- 定义一个函数,用于从命令行参数中解析文件名和选项。
程序首先会读取命令行参数并对其进行解析。最后一个参数会被解释为文件名,而其余参数则作为可选参数处理。 如果无法从命令行中提取文件名,则会打印帮助文本;否则,从文件中读取内容。这些选项用于通过切换不同函数定义来改变程序行为。
该应用程序会生成带行号的文本,将其转换为人类可读的形式,然后打印输出,最后程序退出。以下是其具体实现:
代码清单 4.16:为文本添加行号的主模块
readLines :: FilePath -> IO [String] -- #1
readLines filePath = do
contents <- readFile filePath
return (lines contents)
main :: IO ()
main = do
cliArgs <- getArgs -- #2
let (mFilePath, options) = parseArguments cliArgs -- #3
numberFunction = -- #4
if SkipEmptyLines `elem` options
then numberNonEmptyLines
else numberAllLines
padMode = -- #5
if LeftAlign `elem` options
then PadRight
else PadLeft
let go filePath = do
fileLines <- readLines filePath -- #6
let numbered = numberFunction fileLines -- #7
prettyNumbered = prettyNumberedLines padMode numbered -- #8
revNumbered = numberFunction (reverse fileLines) -- #9
revPretty = reverse (prettyNumberedLines padMode revNumbered)
mapM_
putStrLn
( if ReverseNumbering `elem` options -- #10
then revPretty
else prettyNumbered
)
maybe
(printHelpText "Missing filename") -- #11
go -- #12
mFilePath
说明:
- 读取文件内容并按行拆分。
- 读取程序执行时的命令行参数。
- 解析参数,提取文件名及选项。
- 根据
--skip-empty选项选择行号生成函数。 - 根据
--left-align选项选择左或右对齐模式。 - 读取文件内容。
- 使用选定的编号函数为行添加行号。
- 将行号转换为可读格式。
- 对行进行反转后重新编号与格式化。
- 根据
--reverse选项决定输出正常或反向行号。 - 若未提供文件名,打印帮助信息。
- 若提供文件名,则执行正常流程。
主函数定义了程序的主要逻辑。是否执行取决于参数解析是否得到有效文件路径。
💡 练习:添加更多选项
你可能已经注意到,我们没有使用 numberAndIncrementNonEmptyLines 函数。这个函数不仅跳过空行编号,还不增加计数器。此外,当前的参数解析还很粗糙:未检查无效参数;缺少 --help 选项用于显示帮助文本。请将这些功能添加到程序中!
除此之外,你可以为该工具添加更多功能,例如:不打印空行;仅在新段落时增加计数。功能的扩展几乎是无穷无尽的!如果需要灵感,可以参考 GNU 的 nl 工具。发挥创意吧!
库模块包含行号数据类型的定义以及创建这些行号的工具函数。其导出列表如下:
module Lib
( NumberedLine,
NumberedLines,
isEmpty,
isNotEmpty,
numberLines,
numberAllLines,
numberNonEmptyLines,
numberAndIncrementNonEmptyLines,
prettyNumberedLines,
PadMode (..),
pad,
padLeft,
padRight,
)
where
与行号相关的定义如下代码所示。
代码清单 4.17:库模块的头部、数据类型和工具函数
import Data.Char -- #1
type NumberedLine = (Maybe Int, String) -- #2
type NumberedLines = [NumberedLine] -- #2
isEmpty :: String -> Bool -- #3
isEmpty str =
null str
|| all (\s -> not (isPrint s) || isSeparator s) str
isNotEmpty :: String -> Bool -- #4
isNotEmpty str = not (isEmpty str)
说明:
- 导入
Data.Char模块。 - 定义行号类型。
- 定义用于判断字符串是否为空的布尔谓词。
- 定义用于判断字符串是否非空的布尔谓词。
还包含了一些用于从字符串列表创建 NumberedLines 值的函数,如下代码所示。这些函数构成了我们与该模块交互的接口。
代码清单 4.18:从字符串列表创建带行号的函数
numberLines :: (String -> Bool) -> (String -> Bool) -> [String] -> NumberedLines
numberLines shouldIncr shouldNumber text =
let go :: Int -> [String] -> NumberedLines
go _ [] = []
go counter (x : xs) =
let mNumbering = if shouldNumber x then Just counter else Nothing -- #3
newCounter = if shouldIncr x then counter + 1 else counter -- #3
in (mNumbering, x) : go newCounter xs
in go 1 text
numberAllLines :: [String] -> NumberedLines
numberAllLines = numberLines (const True) (const True)
numberNonEmptyLines :: [String] -> NumberedLines
numberNonEmptyLines = numberLines (const True) isNotEmpty
numberAndIncrementNonEmptyLines :: [String] -> NumberedLines
numberAndIncrementNonEmptyLines = numberLines isNotEmpty isNotEmpty
说明:
- 定义了一个可定制的行编号函数,两个谓词分别决定是否计数、是否编号。
- 局部定义递归辅助函数。
- 基于布尔谓词计算当前行号与下一行的计数器值。
- 通过偏函数定义了具体的编号策略函数。
最后,我们还定义了一些函数,用于将带行号的内容转换为人类可读的形式。这一部分的代码如下表所示。请注意,我们同样可以在其他程序中复用这段代码!这正是我们将其实现为**库模块(library module)**的原因。
代码清单 4.19:将带行号的行转换成人类可读的字符串
prettyNumberedLines :: PadMode -> NumberedLines -> [String]
prettyNumberedLines mode lineNums =
let (numbers, text) = unzip lineNums -- #2
numberStrings = map (maybe "" show) numbers -- #3
maxLength = maximum (map length numberStrings) -- #4
paddedNumbers = map (pad mode maxLength) numberStrings-- #5
in zipWith (\n l -> n ++ " " ++ l) paddedNumbers text -- #5
data PadMode = PadLeft | PadRight -- #6
pad :: PadMode -> Int -> String -> String -- #7
pad mode n str =
let diff = n - length str
padding = replicate diff ' '
in case mode of -- #8
PadLeft -> padding ++ str
PadRight -> str ++ padding
padLeft :: Int -> String -> String = pad PadLeft -- #9
padRight :: Int -> String -> String = pad PadRight -- #9
说明:
- 定义一个将编号行转换为可读文本的函数。
- 拆分编号与文本。
- 将行号转换为字符串。
- 计算最长行号的长度。
- 统一补齐行号长度并拼接文本。
- 定义枚举类型,区分左填充或右填充。
- 定义填充函数,用空格补齐指定长度。
- 根据填充模式决定空格方向。
- 提供左右填充的快捷函数。
理解我们如何在库模块中封装纯代码,并将其整合到可执行模块中的非纯代码中,这一点非常重要。我们实际上是在将纯与非纯混合使用,但同时保持那些提供主要功能的关键函数不受任何副作用影响!
总结
readFile和writeFile用于读写文件系统中的文件。- 函数可以接收其他函数作为参数,从而影响控制流和数据流。
let可用于在函数内部定义辅助函数,用于隐藏递归所需的额外参数。- η(Eta)化简 可用于省略不必要的函数参数,使定义更简洁。
- 部分应用(partial application) 允许通过提供部分参数来生成新的函数。
data关键字用于定义代数数据类型(Sum Type),用于表示可区分的值。zip与zipWith用于按元素组合两个列表。mapM可用于对带有副作用的操作进行映射;mapM_则忽略其结果。