第 11 章 - 用户级 API (User-Level API)
在 BeOS 上,有两种用户级 API 可用于访问文件和目录。BeOS 支持 POSIX 文件 I/O API,它提供了路径名和文件描述符的标准概念。此 API 有一些扩展,允许访问属性、索引和查询。我们只会简要讨论标准的 POSIX API,并花更多时间在扩展上。访问 BeOS 上文件的另一个 API 是 C++ Storage Kit。C++ API 是一个完整的类层次结构,旨在让 C++ 程序员感到宾至如归。本章大部分时间将讨论 C++ API。然而,本章并非旨在作为编程手册。(有关本章中提及函数的更多具体信息,请参阅《Be 开发者指南》)。
11.1 POSIX API 及 C 语言扩展 (The POSIX API and C Extensions)
所有标准的 POSIX 文件 I/O 调用,例如 open()、read()、write()、dup()、close()、fopen()、fprintf() 等等,在 BeOS 上都能按预期工作。直接操作文件描述符的 POSIX 调用(即 open()、read() 等)是直接的内核调用。内核提供的文件描述符模型直接支持 POSIX 文件描述符模型。尽管一些 BeOS 开发者曾施压要发明新的文件 I/O 机制,但我们决定不重复造轮子。即使是 BeOS C++ API,其 C++ 外壳之下也使用了文件描述符。POSIX 文件 I/O 模型工作得很好,我们认为改变该模型没有任何优势。
属性函数 (Attribute Functions)
C 语言接口的属性功能包含八个函数。前四个函数提供了一种枚举与文件关联属性的方法。一个文件可以有任意数量的属性,与文件关联的属性列表以属性目录的形式呈现。访问与文件关联的属性列表的 API 几乎与 POSIX 目录函数(opendir()、readdir() 等)完全相同:
DIR *fs_open_attr_dir(char *path);struct dirent *fs_read_attr_dir(DIR *dirp);int fs_rewind_attr_dir(DIR *dirp);int fs_close_attr_dir(DIR *dirp);
此 API 与 POSIX 目录 API 的相似性使其能够立即被任何熟悉 POSIX API 的程序员使用。我们在这里和其他地方的意图是重用程序员已经熟悉的概念。fs_read_attr_dir() 返回的每个命名条目都对应于 fs_open_attr_dir() 给定路径所指向文件的一个属性。
接下来的四个函数提供对单个属性的访问。同样,我们坚持使用 POSIX 程序员熟悉的概念。第一个例程返回有关特定属性的更详细信息:
int fs_stat_attr(int fd, char *name, struct attr_info *info);
此函数用指定属性的类型和大小填充 attr_info 结构。
值得注意的是这里选择的 API 风格:为了识别文件的属性,程序员必须指定属性所关联的文件描述符和属性的名称。这也是其余属性函数的风格。如第 10 章所述,将属性变成完整的文件描述符会使文件删除变得异常复杂。不将属性视为文件描述符的决定体现在这里的用户级 API 中,其中属性总是通过提供文件描述符和名称来识别。
下一个函数从文件中删除一个属性:
int fs_remove_attr(int fd, char *name);
在此调用之后,该属性不再存在。此外,如果属性名称被索引,则该文件将从关联的索引中移除。
接下来的两个函数提供了读写属性的 I/O 接口:
ssize_t fs_read_attr(int fd, char *name, uint32 type, off_t pos, void *buffer, size_t count);ssize_t fs_write_attr(int fd, char *name, uint32 type, off_t pos, void *buffer, size_t count);
此 API 严格遵循我们在较低层描述的内容。每个属性都有一个名称、一个类型以及与名称关联的数据。文件系统可以使用类型代码来确定是否可以索引该属性。如果指定名称的属性不存在,fs_write_attr() 会创建它。这两个函数完善了 POSIX 风格 API 对属性的接口。
索引函数 (Index Functions)
索引功能的接口仅由简单的 C 语言接口提供。没有对应的 C++ API 用于索引例程。这并非反映了我们的语言偏好,而是认识到为这些例程编写 C++ 包装器获益甚微。索引 API 提供了遍历卷上索引列表以及创建和删除索引的例程。用于遍历卷上索引列表的例程是:
DIR *fs_open_index_dir(dev_t dev);struct dirent *fs_read_index_dir(DIR *dirp);int fs_rewind_index_dir(DIR *dirp);int fs_close_index_dir(DIR *dirp);
同样,此 API 与 POSIX 目录函数非常相似。fs_open_index_dir() 接受一个 dev_t 参数,vnode 层通过它知道要操作哪个卷。fs_read_index_dir() 返回的条目提供了每个索引的名称。要获取有关索引的更多信息,调用是:
int fs_stat_index(dev_t dev, char *name, struct index_info *info);
fs_stat_index() 调用返回一个类似 stat 结构的信息,其中包含有关命名索引的类型、大小、修改时间、创建时间和所有权等字段,这些都包含在 index_info 结构中。
创建索引通过以下方式完成:
int fs_create_index(dev_t dev, char *name, int type, uint flags);
此函数在指定卷上创建命名索引。flags 参数目前未使用,但将来可能指定其他选项。索引具有由 type 参数指示的数据类型。支持的类型有:
- 整数(有符号/无符号,32-/64-位)
- 浮点数
- 双精度浮点数
- 字符串
文件系统可以允许其他类型,但这些是 BFS 支持的数据类型(目前 BeOS 上唯一支持索引的文件系统是 BFS)。
索引的名称应与将添加到文件的属性的名称对应。文件系统创建索引后,所有添加了名称(和类型)与此索引匹配的属性的文件,其属性值也将添加到索引中。
删除索引几乎太容易了:
int fs_remove_index(dev_t dev, char *name);
调用 fs_remove_index() 后,索引即被删除,不再存在。删除索引是一个严肃的操作,因为一旦索引被删除,其中包含的信息无法轻易重新创建。删除仍然需要的索引可能会干扰需要该索引的程序的正常运行。几乎无法防止某人无意中删除索引,因此除了命令行工具(调用此函数)之外,不提供其他接口来删除索引。
查询函数 (Query Functions)
查询是关于文件属性的表达式,例如 name = foo 或 MAIL:from != pike@research.att.com。查询的结果是匹配表达式的文件列表。遍历匹配文件列表的显而易见的 API 风格是标准的目录风格 API:
DIR *fs_open_query(dev_t dev, char *query, uint32 flags);struct dirent *fs_read_query(DIR *dirp);int fs_close_query(DIR *dirp);
尽管此 API 看起来异常简单,但它与一个非常强大的机制连接。通过查询,程序可以将文件系统用作数据库,以基于其在层次结构中固定位置以外的条件来查找信息。fs_open_query() 参数接受一个设备参数,指示在哪个卷上执行查询;一个表示查询的字符串;以及一个(目前未使用的)flags 参数。文件系统使用查询字符串查找与表达式匹配的文件列表。每个匹配的文件都通过连续调用 fs_read_query() 返回。不幸的是,返回的信息不足以获取文件的完整路径名。C API 在这方面有所欠缺,需要一个函数将 dirent 结构转换为完整的路径名。尽管在大多数版本的 Unix 上不可行,但在 BeOS C++ API 中,从 dirent 到完整路径名的转换是可能的。
查询的 C API 也不支持实时查询。这很不幸,但发送实时查询更新的机制本质上是基于 C++ 的。尽管可以提供包装器来封装 C++ 代码,但没有足够的动机这样做。查询的 C 接口是为了在调试阶段(在 C++ API 编码之前)支持原始测试应用程序,并允许 C 程序访问扩展的 BFS 功能而编写的。未来可能会进一步改进查询的 C 接口,使其更有用。
卷函数 (Volume Functions)
这最后一组 C 语言接口提供了一种方法来查找文件的设备 ID,遍历可用设备 ID 列表,并获取由设备 ID 表示的卷的信息。这三个函数是:
dev_t dev_for_path(char *path);int fs_stat_dev(dev_t dev, fs_info *info);dev_t next_dev(int32 *pos);
第一个函数 dev_for_path() 返回包含 path 所指向文件的卷的设备 ID。此调用没有什么特别之处;它只是一个便捷调用,是 POSIX 函数 stat() 的一个包装。
fs_stat_dev() 函数返回有关指定设备 ID 标识的卷的信息。返回的信息类似于 stat 结构,但包含诸如设备的块总数、已使用块数、卷上的文件系统类型以及指示文件系统支持哪些功能(查询、索引、属性等)的标志等字段。这是 df 等命令行工具打印信息时使用的函数。
next_dev() 函数允许程序遍历所有设备 ID。pos 参数是指向一个整数的指针,在第一次调用 next_dev() 之前应将其初始化为零。当没有更多设备 ID 可返回时,next_dev() 返回一个错误代码。使用此例程,可以轻松遍历所有挂载的卷,获取它们的设备 ID,然后对该卷执行或使用它(例如,执行查询,获取卷的卷信息等)。
POSIX API 和 C 语言总结 (POSIX API and C Summary)
BeOS 提供的 C API 涵盖了所有标准的 POSIX 文件 I/O,并且扩展具有非常 POSIX 化的感觉。保持 API 熟悉的设计理念推动了扩展 API 的设计。这些函数允许 C 程序以最小的麻烦访问 BeOS 提供的大多数功能。
11.2 C++ API (The C++ API)
BeOS 用于操作文件和执行 I/O 的 C++ API 经历了艰难的诞生过程。许多因素在 POSIX 领域和 Macintosh 式文件处理的极端之间反复推动着设计。API 多次改变,类层次结构也多次变异,在发布前仅两周,API 又经历了一次痉挛式的变化。这种混乱的过程是由于试图迎合太多不同的需求而导致的。最终,似乎没有人特别满意。尽管该 API 功能齐全且使用起来不过分繁重,但每个参与设计的人都会以略微不同的方式来做,并且该 API 的某些部分有时仍然显得古怪。出现的问题从未出在实现上,而是在设计上:如何构造类以及每个类中提供哪些功能。本节将讨论类层次结构的设计问题,并尝试说明设计文件访问 C++ API 的难度。
类层次结构 (The Class Hierarchy)
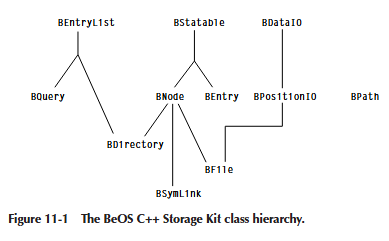
图 11-1 显示了 C++ Storage Kit 的类层次结构。所有三个基类都是纯虚类。也就是说,它们只定义了所有派生类的基本功能级别,但它们不实现任何功能。程序永远不会直接实例化这些类中的任何一个;它只会实例化其中一个派生类。BPath 类独立存在,可用于主层次结构中其他对象的构造。我们对类层次结构的描述侧重于类之间的关系及其总体结构,而不是编程细节。
概念 (The Concepts)
C++ API 基于两个基本概念:条目 (entry) 和节点 (node)。条目是一个句柄,通过其在文件系统层次结构中的位置来引用文件。条目是抽象的,因为它引用一个命名条目,无论它是一个文件还是目录。条目不一定实际存在。例如,如果编辑器即将保存新文件 /SomeDisk/file.c,它会创建一个条目来引用该文件名,但该条目直到程序创建它时才存在。在 C++ API 中,条目可以有多种形式:路径名 (path name)、条目引用 (entry ref) 或 BEntry 对象。这些项中的每一个都具有不同的属性和行为。
节点是一个句柄,用于引用文件中包含的数据。节点的概念,用 POSIX 术语来说,就是文件描述符。换句话说,节点是一个句柄,允许程序读取和写入文件系统中命名条目中的数据(和属性)。在 C++ API 中,节点可以有多种形式,包括 BNode、BDirectory、BSymLink 和 BFile。
条目和节点之间的关键区别在于:条目操作整个文件以及关于文件或目录的数据。节点操作条目的内容。条目是对文件系统层次结构中命名对象(可能尚未存在)的引用,而节点是对已存在的条目内容的句柄。
这种功能上的区别可能看起来不寻常。自然会问,为什么 BEntry 对象不能访问它所引用文件中的数据,以及为什么 BFile 不能重命名自己?文件系统中对象的名称(条目)与其内容(节点)之间的区别是显著的,并且两者不能合并。程序可以打开一个文件名,如果它引用一个真实文件,该文件就会被打开。然而,打开该文件后,该文件名就可能变得过时。也就是说,一旦文件名被创建或打开,文件名可能会改变,从而使原始名称过时。尽管文件名在大多数情况下是静态的,但名称和内容之间的联系是脆弱的,并且可以随时改变。如果文件描述符能够返回其名称,该名称可能会立即改变,从而使信息过时。反之,如果 BEntry 对象也能访问其名称所引用的数据,那么底层对象的名称可能会在对 BEntry 的写入之间发生变化,这将导致写入的数据最终进入两个不同文件的内容中。为了避免返回过时信息以及可能由此引发的问题,C++ API 中将条目和节点分离开来。
条目 (The Entries)
有三种条目类型对象:BPath、entry ref 和 BEntry。
BPath (BPath)
C++ 是一种将简单概念用一个漂亮的对象封装起来的绝佳语言。BPath 对象就是将路径名封装在 C++ 对象中的一个很好的例子。BPath 对象允许程序员构建路径名,而无需担心内存分配或字符串操作。
BPath 对象可以:
- 连接路径名
- 剥离完整路径名的叶子部分
- 仅返回叶子部分
- 验证路径名是否指向有效文件
这些操作并不复杂,但将它们封装在一个方便的对象中是很有帮助的(即使对于那些顽固的 Unix 黑客也是如此)。BPath 对象提供了处理路径名的便捷方法,管理着内存分配和字符串操作的细节。
条目引用 (entry ref)
路径名是按其位置引用文件的最基本方式。它明确,用户理解,并且可以安全地存储在磁盘上。路径名的缺点是它们脆弱:如果程序存储了一个路径名,并且文件名中的任何组件发生变化,路径名就会失效。你是否喜欢使用路径名,似乎归结为你是否喜欢编写 Macintosh 操作系统的程序。POSIX 狂热者无法想象任何其他引用文件的机制,而 Macintosh 狂热者无法想象程序在找不到所需文件时如何运行。
讨论路径名使用的典型争论大致如下:
“如果我的程序存储了一个完整路径名,并且路径的某个部分发生变化,那么我的程序就坏了。”
“不要存储完整路径名。存储相对于当前目录的路径。”
“但是,我如何将路径名传递给可能具有不同当前目录的另一个程序呢?”
“嗯……”
这种争论的另一面大致如下:
“我有一个错误的配置文件,导致你的程序崩溃。我把它重命名为 config.bad,但因为你没有使用路径名,你的程序仍然引用那个坏的配置文件。”
“那你应该把文件扔掉。”
“但我不想扔掉它。我需要保存它,因为我想找出问题所在。我怎样才能让你的程序停止引用这个文件?”
以各种形式,这两种争论重复了太多次。我们无法想出一种能同时满足双方阵营的方法。想要存储文件直接句柄(本质上是其 i-node 号码)的程序员不希望与路径名有任何关系。只理解路径名的程序员无法想象存储用户一无所知的东西。
此外,还出现了其他技术问题。一个担忧是如果允许用户程序直接将 i-node 号码传递给文件系统,则很难强制执行文件安全性。另一个更严重的问题是,BFS 中的 i-node 号码只是磁盘地址,允许用户程序加载任意 i-node 号码会打开一个巨大的漏洞,不正确或恶意程序可能利用它来导致文件系统崩溃。
我们对这个棘手问题的折衷解决方案是 entry_ref 结构,它是两种风格的混合。entry_ref 存储文件的名称以及包含该文件的目录的 i-node。存储在 entry_ref 中的名称只是文件在目录中的名称,而不是完整路径名。entry_ref 结构解决了第一个争论,因为如果目录在文件系统层次结构中的位置发生变化,entry_ref 仍然有效。它也解决了第二个争论,因为存储的名称允许用户重命名文件以防止其被使用。当然,仍然存在问题:如果一个目录被重命名以阻止使用其中的任何文件,entry_ref 仍将引用旧文件。另一个主要问题是 entry_ref 仍然需要加载任意 i-node。
entry_ref 功能没有让任何人觉得“理想”或“正确”。但产品发布的需要让我们吞下了妥协的苦果。有趣的是,在设计接近尾声时,当 Macintosh 风格的程序员妥协并决定路径名也没有那么糟糕时,entry_ref 的使用差点被放弃。更有趣的是,Unix 风格的程序员也妥协了,双方最终提出了与他们最初完全相反的论点。幸运的是,我们决定最好还是保持现有设计,因为很明显任何一方都不能“正确”。
BEntry (BEntry)
第三种条目类型对象是 BEntry。BEntry 是一个 C++ 对象,与 entry_ref 非常相似。BEntry 可以访问有关对象的信息(其大小、创建时间等)并可以修改它们。BEntry 还可以删除自己、重命名自己,并将其移动到另一个目录。
如果程序想要对文件(不是文件内容,而是整个文件)执行操作,它将使用 BEntry。BEntry 是 C++ API 中用于操作文件信息的主力。
节点对象:BNode (The Node Object: BNode)
BNode 对象底层是一个 POSIX 风格的文件描述符。BNode 对象实际上不实现任何文件 I/O 函数,但它实现了属性调用。这是因为 BDirectory 和 BFile 都派生自 BNode,而目录不能像文件一样进行写入。BNode 只包含所有文件描述符共享的功能,无论其类型如何。
BNode 对象主要允许访问文件的属性。程序可以使用派生对象(如 BFile 或 BDirectory,稍后讨论)访问条目的内容。BNode 还允许程序锁定对节点的访问,以便在程序解锁节点(或退出)之前不会进行其他修改。BNode 很简单,派生类实现了大部分功能。
BEntryList (BEntryList)
正如我们在 C API 中看到的,用于遍历目录、文件属性和查询结果的函数集都非常相似。BEntryList 对象是一个纯虚类,它抽象了遍历条目列表的过程。BDirectory 和 BQuery 对象为其各自类型的对象实现了具体的功能。
BEntryList 定义的三个有趣方法是 GetNextEntry、GetNextRef 和 GetNextDirents。这些例程以 BEntry 对象、entry_ref 结构或 dirent 结构的形式返回目录中的下一个条目。这些例程都执行相同的任务,但以不同的形式返回信息。GetNextDirents() 方法只是 readdir() 使用的底层系统调用的一个薄包装。GetNextRef() 函数返回一个封装目录条目的 entry_ref 结构。entry_ref 结构可以更直接地被 C++ 代码使用,尽管创建该结构会带来轻微的性能损失。GetNextEntry() 返回一个完整的 BEntry 对象,这涉及为包含条目的目录打开文件描述符并获取有关文件的信息。这些任务使得 GetNextEntry() 成为这三个访问函数中最慢的一个。
抽象的 BEntryList 对象定义了遍历文件集的机制。派生类实现目录和查询的具体功能。BEntryList 定义的 API 与 POSIX 目录风格的函数有一些相似之处,尽管 BEntryList 能够返回每个条目更复杂(和有用)的信息。
BQuery (BQuery)
BEntryList 的第一个派生类是 BQuery。在 BeOS 中,查询呈现为与文件属性表达式匹配的文件列表。将查询视为文件列表使得 BQuery 成为 BEntryList 的自然后代,允许遍历一组文件。BQuery 实现了访问函数,以便它们返回查询的连续结果。
有两种接口用于指定查询表达式。第一种方法接受使用中缀表示法的表达式字符串,非常类似于 C 或 C++ 中的表达式。另一种方法使用基于堆栈的后缀表示法接口。中缀字符串 name = foo.c 也可以表示为以下一系列后缀操作:
push attribute "name"
push string "foo.c"
push operator =
BQuery 对象在内部将基于堆栈的后缀运算符转换为中缀字符串,然后将其传递给内核。
BQuery 对象有一个方法,允许程序员指定一个端口来发送更新消息。设置此端口表明查询应该是实时的(即,当与查询匹配的文件集随时间变化时,会发送更新)。端口的细节相对不重要,除了它们为程序提供了一个接收消息的地方。在实时查询的情况下,文件系统会将消息发送到端口,通知程序查询的更改。
BStatable (BStatable)
下一个纯虚基类 BStatable 定义了程序可以对文件系统中条目或节点的统计信息执行的一组操作。BStatable 类提供的方法有:
- 确定所引用的节点类型(文件、目录或符号链接等)
- 获取/设置节点的拥有者、组和权限
- 获取/设置节点的创建、修改和访问时间
- 获取节点数据的大小(不包括属性)
BEntry 和 BNode 对象派生自 BStatable 并实现了条目和节点的具体功能。重要的是要注意,BStatable 对象定义的方法适用于条目和节点。这乍一看可能像是违反了本节前面讨论的原则,但它并没有违反我们之前提出的原则,因为 BStatable 可以获取或设置的信息始终随文件一起保留,无论文件是移动、重命名还是删除。
BEntry 再探 (BEntry Revisited)
前面讨论过,BEntry 对象派生自 BStatable。BEntry 对象在 BStatable 的基础上增加了重命名其引用的条目、移动条目和删除条目的能力。BEntry 对象包含一个包含文件的目录的文件描述符和文件的名称。BEntry 是在对文件进行整体操作(例如重命名)时,用于操作文件的主要对象。
BNode 再探 (BNode Revisited)
前面也讨论过,BNode 对象的核心是一个文件描述符。由于其在类层次结构中的位置,BNode 中没有定义任何文件 I/O 方法。子类 BFile 实现了 BNode 中包含的文件描述符上的必要文件 I/O 方法。BNode 实现了属性方法,可以:
- 读取属性
- 写入属性
- 删除属性
- 遍历属性列表
- 获取属性的扩展信息
BNode 对象还可以锁定一个节点,以便在程序解锁节点(或退出)之前不会进行其他访问。BNode 还可以强制文件系统刷新其可能属于该文件的任何缓冲数据。就其本身而言,BNode 对象的用处有限。如果程序只关心操作文件的属性、锁定文件或将其数据刷新到磁盘,那么 BNode 就足够了;否则,派生类更合适。
BDirectory (BDirectory)
BDirectory 对象派生自 BEntryList 和 BNode,它使用 BEntryList 定义的迭代函数和 BNode 提供的文件描述符来允许程序遍历目录的内容。除了其作为遍历目录内容的主要功能外,BDirectory 还具有以下方法:
- 测试名称是否存在
- 创建文件
- 创建目录
- 创建符号链接
与其他 BNode 派生对象不同,BDirectory 对象可以从自身创建 BEntry 对象。您可能会质疑这是否会打破前面讨论的过时问题。BDirectory 对象能够为自身创建 BEntry 的能力取决于一个事实:BeOS 中文件系统中的每个目录都有“.”(当前目录)和“..” (当前目录的父目录)的条目。这些名称是符号性的,而不是对特定名称或 i-node 号码的引用,这避免了过时问题。
BSymLink (BSymLink)
符号链接对象 BSymLink 派生自 BNode,允许访问符号链接的内容,而不是它指向的对象。在大多数情况下,程序不需要实例化 BSymLink 对象,因为符号链接与大多数只需要读写数据的程序无关。然而,一些程序(例如 Tracker,BeOS 文件浏览器)在条目是符号链接时需要显示不同的内容。BSymLink 类提供了允许程序读取链接内容(即它“指向”的路径)和修改链接中包含的路径的方法。BSymLink 中几乎不需要或不提供其他功能。
BDataIO/BPositionIO (BDataIO/BPositionIO)
这两个抽象类不严格属于 C++ 文件层次结构;相反,它们来自其他 Be 对象使用的通用类支持库。BDataIO 仅声明了基本的 I/O 函数 Read() 和 Write()。BPositionIO 声明了一组额外的函数(ReadAt()、WriteAt()、Seek() 和 Position()),用于可以跟踪 I/O 缓冲区中当前位置的对象。这两个类只定义了 API。它们不实现任何功能。派生类为特定类型的对象(文件、内存、网络等)实现 I/O 的具体功能。
BFile (BFile)
我们对这个类层次结构的最后一站是 BFile 对象。BFile 派生自 BNode 和 BPositionIO,这意味着它既可以对文件内容执行真实的 I/O,也可以操作文件的一些统计信息(拥有者、权限等)。BFile 是程序用于执行文件 I/O 的对象。
尽管对于这样一个重要的对象来说,这似乎几乎是虎头蛇尾,但关于 BFile 并没有太多值得说的重要内容。它在引用常规文件的文件描述符的上下文中实现了 BDataIO/BPositionIO 函数。它还实现了 BStatable/BNode 的纯虚方法,以允许获取和设置文件的统计信息。BFile 不提供任何额外功能,并提供对底层文件描述符执行文件 I/O 的直接访问。
节点监视器 (Node Monitoring)
用户级 API 的最后一个组件称为节点监视器。尽管节点监视器不属于上面定义的类层次结构,但它仍然是 C++ API 的一部分。节点监视器是一项服务,允许程序请求接收文件系统更改的通知。您可以要求在以下情况发生时得到通知:
- 目录内容发生更改
- 条目的名称发生更改
- 条目的任何属性发生更改(即,统计信息)
- 条目的任何属性发生更改
应用程序程序使用节点监视器来动态响应用户所做的更改。BeOS 网页浏览器 NetPositive 将其书签存储为目录中的文件,并监视该目录的更改以更新其书签菜单。其他程序监视数据文件,以便如果数据文件发生更改,程序可以刷新正在使用的内存中版本。节点监视器还有许多其他用途。这些示例只是演示了两种可能性。
通过围绕底层节点监视器的包装 API,程序还可以在以下情况发生时接收通知:
- 卷被挂载
- 卷被卸载
与查询向端口发送实时更新通知的方式相同,当发生有趣的事情时,节点监视器也会向端口发送消息。“有趣”事件是指与程序表示感兴趣的更改相匹配的事件。例如,程序可以要求只接收对文件属性更改的通知;如果被监视的文件被重命名,则不会发送通知。
节点监视器监视特定的文件或条目。如果程序希望接收目录中任何文件更改的通知,它必须对该目录中的所有文件发出节点监视器请求。如果程序只希望接收目录中文件创建或删除的通知,那么它只需要监视该目录。
围绕节点监视器没有构建复杂的类。程序通过两个简单的 C++ 函数 watch_node() 和 stop_watching() 访问节点监视器。
11.3 使用 API (Using the API)
尽管我们对 BeOS C++ Storage Kit 的讨论提供了一个很好的高层概述,但它并没有展现编程 API 的具体细节。
通过一个使用 BeOS Storage Kit 的具体示例,将有助于完成循环,并使 API 更加直观。
在这个示例中,我们将接触 BeOS Storage Kit 的大部分功能,以编写一个程序:
- 创建一个关键词索引
- 遍历文件目录,为每个文件生成关键词
- 将关键词作为文件属性写入
- 对关键词索引执行查询,查找包含特定关键词的文件
尽管该示例省略了一些细节(例如如何合成简短的关键词列表)和一些错误检查,但它确实演示了 Storage Kit 类的实际应用。
设置 (The Setup)
在生成任何关键词或添加属性之前,我们的示例程序首先创建关键词索引。这一步是必要的,以确保所有关键词属性都将被索引。任何打算使用索引的程序都应在生成任何需要索引的属性之前始终创建索引。
#define INDEX_NAME "Keyword"
main(int argc, char **argv){
BPath path(argv[1]);
dev_t dev;
/*
首先,我们将获取此路径所指向文件系统的设备句柄,
然后我们将使用它来创建我们的“Keyword”索引。
请注意,如果索引已经存在并且我们再次创建它,不会造成任何损害。
*/
dev = dev_for_path(path.Path());
if (dev < 0)
exit(5);
fs_create_index(dev, INDEX_NAME, B_STRING_TYPE, 0);
生成属性 (Generating the Attributes)
程序的下一阶段是遍历路径所引用的目录中的所有文件。程序在一个单独的函数 generate_keywords() 中完成这项工作,main() 函数会调用它。main() 函数将其 BPath 对象传递给 generate_keywords(),以指示要遍历哪个目录。
void generate_keywords(BPath *path){
BDirectory dir;
entry_ref ref;
dir.SetTo(path->Path());
if (dir.InitCheck() != 0) /* hmmm, dir doesn’t exist? */
return;
while(dir.GetNextRef(&ref) == B_NO_ERROR) {
char *keywords;
BFile file;
file.SetTo(&ref, O_RDWR);
keywords = synthesize_keywords(&file);
file.WriteAttr(INDEX_NAME, B_STRING_TYPE, 0, keywords, strlen(keywords)+1);
free(keywords);
}
}
例程的第一部分初始化 BDirectory 对象并检查它是否指向有效目录。generate_keywords() 的主循环在调用 GetNextRef() 时进行迭代。每次调用 GetNextRef() 都会返回目录中下一个条目的引用,直到没有更多条目为止。GetNextRef() 返回的 entry_ref 对象用于初始化 BFile 对象,以便可以读取文件内容。
接下来,generate_keywords() 调用 synthesize_keywords()。尽管我们省略了细节,但 synthesize_keywords() 可能会读取文件内容并生成一个关键词列表作为字符串。
合成关键词列表后,我们的示例程序使用 WriteAttr() 函数将这些关键词作为文件属性写入。写入关键词属性也会自动索引关键词,因为关键词索引已经存在。
C++ BFile 对象的一个出色功能是,每次调用 SetTo() 时,它都会正确处理任何以前的文件引用,并且在销毁时会自动清理使用的任何资源。此功能消除了在操作许多文件时文件描述符泄漏的可能性。
发出查询 (Issuing a Query)
我们示例的最后一部分展示了如何对包含特定关键词的文件发出查询。发出查询的设置几乎没有意外。我们为查询构建了谓词,它是一个包含表达式 Keyword = *<word>* 的字符串。查询的 <word> 部分是函数的一个字符串参数。查询周围使用星号使其成为子字符串匹配。
void do_query(BVolume *vol, char *word){
char buff[512];
BQuery query;
BEntry match_entry;
BPath path;
sprintf(buff, "%s = *%s*", INDEX_NAME, word);
query.SetPredicate(buff);
query.SetVolume(vol);
query.Fetch();
while(query.GetNextEntry(&match_entry) == B_NO_ERROR) {
match_entry.GetPath(&path);
printf("%s\n", path.Path());
}
}
设置查询的最后一步是使用 SetPredicate() 指定要在哪个卷上发出查询。要启动查询,我们调用 Workspace()。当然,实际程序会检查 Workspace() 返回的错误。
查询的最后阶段是通过调用 GetNextEntry() 来遍历结果。这与我们上面 generate_keywords() 函数中遍历目录的方式类似。调用 GetNextEntry() 而不是 GetNextRef() 允许我们获取匹配查询的文件路径。对于我们这里的目的,路径是我们感兴趣的全部内容。如果需要打开和读取文件,那么调用 GetNextRef() 可能更合适。
这个示例的重点不是创建关键词属性的具体情况,而是展示程序轻松整合这些功能的方式。只需几行代码,程序就可以添加属性和索引,从而获得基于这些属性发出查询的能力。
11.4 总结 (Summary)
BeOS 的两个用户级 API 暴露了 BeOS vnode 层支持并由 BFS 实现的功能。BeOS 支持传统的 POSIX 文件 I/O API(带有一些扩展)和一个完全面向对象的 C++ API。C++ API 提供了诸如实时查询和节点监视等传统 C API 无法访问的功能。只能从 C 访问的函数是用于遍历、创建和删除索引的索引函数。
C++ API 的设计引发了倡导 Macintosh 风格文件处理方法和倡导 POSIX 风格的两者之间的冲突。在 BeOS 文件 I/O 的类层次结构中编纂的折衷解决方案是可以接受且有效的,即使设计中的某些部分看起来不那么理想。