第 4 章 - BFS的数据结构 (The Data Structures of BFS)
4.1 什么是磁盘?(What Is a Disk?)
BFS(Be File System)将磁盘视为一个线性块数组,并在此基础抽象之上管理其所有数据结构。最底层,原始设备(如 SCSI 或 IDE 磁盘)都有一个设备块大小的概念,通常为 512 字节。BFS 中的“块”概念建立在原始设备块之上。文件系统块大小与原始设备块大小只有松散的耦合关系。对文件系统块大小的唯一限制是它必须是底层设备块大小的整数倍。也就是说,如果原始设备块大小是 512 字节,那么文件系统块大小可以是 512、1024 或 2048 字节。尽管也可以使用 1536 字节(3×512)这样的块大小,但由于它不是 2 的幂,这在性能上是非常糟糕的选择。虽然并非严格要求,但使用非 2 的幂块大小会对性能产生显著影响。
文件系统块大小还会影响虚拟内存系统(如果系统支持内存映射文件的话)。此外,如果希望将虚拟内存系统与缓冲缓存(buffer cache)统一起来,使文件系统块大小为 2 的幂是必需的(理想情况下,VM 页大小与文件系统块大小相等)。BFS 允许的块大小为 1024、2048、4096 或 8192 字节。我们不允许 512 字节块大小,是因为这样会导致某些关键的文件系统数据结构跨越多个块,给缓存管理和日志(journaling)带来复杂性,也会引起明显的性能下降。至于为什么最大块大小限定为 8192 字节,则需要先理解后面提到的其他结构,届时再作解释。
重要的是要认识到,文件系统块大小与磁盘容量无关(这点不同于 Macintosh HFS)。文件系统块大小的选择应根据磁盘上要存储的文件类型来决定:大量小文件在 8K 块下会造成大量空间浪费;而对于包含大文件的文件系统,则更适合使用更大的块,而非非常小的块。
4.2 如何管理磁盘块 (How to Manage Disk Blocks)
管理磁盘空闲空间的方法有多种,最常见且最简单的是位图(bitmap)方案。其他方法有基于 extent 的和基于 B+ 树的(如 XFS)。BFS 出于简洁考虑,采用了位图方案。
位图方案将每个磁盘块表示为一个比特,文件系统将整个磁盘视为这些比特的数组。如果某个比特为 1,则对应磁盘块已被分配。计算位图所需空间(字节)的公式为:
(disk size in bytes) / (filesystem block size × 8)
例如,对于一个 1 GB、块大小为 1 KB 的磁盘,其位图大小为 128 KB。
位图方案的主要缺点是,要寻找大块连续的空闲空间时,需要线性扫描整个位图。还有人认为,随着磁盘的逐渐填满,位图扫描的成本会增加;但实际上可以证明,查找位图中一个空闲比特的平均成本与位图的填充程度无关。正是因为这一点,加之实现简单,BFS 才使用了位图方案(尽管事后我也希望有时间去尝试其他分配方案)。
位图数据结构在磁盘上以一个连续的字节数组存储(向上取整至块大小的整数倍)。BFS 从块 1 开始存放位图(超级块 superblock 占据块 0)。在创建文件系统时,超级块和位图所占用的块会预先分配好。
4.3 分配组(Allocation Groups)
分配组是纯逻辑结构,没有对应的实际结构体。BFS 将构成文件系统的块数组划分为若干等大区块,称为“分配组”。分配组的概念用于将数据分散存放在磁盘上。
一个分配组就是磁盘上若干连续的块。分配组中块的数量与文件系统块大小及整个磁盘的位图大小密切相关。为了效率和方便,BFS 强制每个分配组的块数为一个位图块所映射块数的整数倍。以一个 1 GB、块大小为 1 KB 的磁盘为例,该磁盘的位图大小为 128 KB,因此占用 128 块。由于每个位图块为 1 KB,可映射 8192 块,故最小分配组大小为 8192 块。由于设计上的其它考量,最大分配组大小始终为 65 536 块。BFS 在选择分配组大小时,会在磁盘容量(对大分配组的需求)与分配组数量(不宜过多)之间进行平衡;实践中,通常用每 GB 空间约 8192 块作为分配组大小的经验值。
如前所述,BFS 使用分配组来分散数据存放。BFS 会尝试将文件的控制信息(i-node)放在与其父目录相同的分配组内;同时,BFS 会尝试将新创建的目录放在与包含它的目录不同的分配组中,文件数据也会放在与其控制信息不同的分配组。这样的布局策略倾向于将同一目录下的文件控制信息聚集在一个分配组,而将文件数据聚集在另一个分配组,从而使同一目录下的文件物理上靠得更近。需要注意的是,这只是一个建议策略;如果磁盘已接近满,唯一可用的空闲空间正好在同一分配组内,BFS 仍会进行分配。
为了提升分配块时的性能,BFS 在内存中维护了每个分配组在位图中的信息。每个分配组都记录了上次分配的空闲块索引,以便下次分配时无需从组开始处线性扫描;此外,还为每个分配组维护了“已满”标志,以便在分配组已无可用空间时,直接跳过对该组位图的扫描。
4.4 块运行(Block Runs)
块运行结构是 BFS 定位磁盘块的基本方式。其定义如下:
typedef struct block_run {
int32 allocation_group;
uint16 start;
uint16 len;
} block_run;
allocation_group字段指出所在的分配组;start字段指出在该分配组内块运行的起始块号;len字段指出该运行包含的块数。
该结构能表示的最大块号为 2^48(当块大小为 1 KB 时,对应最大磁盘容量约 2^58 字节);尽管相比纯 64 位块号略显不足,但 2^58 字节的容量足以存储 217 年的 720×486 分辨率、4 字节/像素、30 帧/秒的未压缩视频,用量远超过可预见的需求。
len 字段为 16 位,最多可表示 65 536 块。对文件系统块大小较大时,单个 8 字节的块运行寻址最多可达数十 MB,已相当实用。但 start 字段也是 16 位无符号数,这意味着单个分配组最多 65 536 块,进而使得 8192 字节成为 BFS 文件系统块大小的上限:若允许更大块,位图每块映射更多块,分配组将超出 start 字段的可寻址范围,导致部分块无法分配。
BFS 将块运行结构用作 i-node 的寻址结构;在 i-node 寻址时,len 字段始终为 1。
4.5 超级块 (Superblock)
BFS 超级块包含许多字段,这些字段不仅描述了文件系统所在卷的物理大小,还包含有关日志区域和索引的附加信息。此外,BFS 存储了一些冗余信息,以便更好地对超级块、卷名和文件系统的字节顺序进行一致性检查。BFS 超级块数据结构如下:
typedef struct disk_super_block {
char name[B_OS_NAME_LENGTH]; // 卷名
int32 magic1; // 魔数1
int32 fs_byte_order; // 文件系统字节顺序
uint32 block_size; // 块大小
uint32 block_shift; // 块移位数
off_t num_blocks; // 总块数
off_t used_blocks; // 已用块数
int32 inode_size; // i-node 大小
int32 magic2; // 魔数2
int32 blocks_per_ag; // 每个分配组的块数
int32 ag_shift; // 分配组移位数
int32 num_ags; // 分配组总数
int32 flags; // 标志
block_run log_blocks; // 日志块区域
off_t log_start; // 日志起始位置
off_t log_end; // 日志结束位置
int32 magic3; // 魔数3
inode_addr root_dir; // 根目录 i-node 地址
inode_addr indices; // 索引 i-node 地址
int32 pad[8]; // 填充字节
} disk_super_block;
你会注意到超级块中存储了三个魔数。挂载文件系统时,这些魔数是确保正确性的第一轮健全性检查。请注意,这些魔数分布在整个数据结构中,这样如果数据结构的任何部分损坏,比仅在结构开头设置一两个魔数更容易检测到损坏。
魔数的值是完全任意的,但被选择为较大且具有一定趣味性的 32 位值:
#define SUPER_BLOCK_MAGIC1 0x42465331 /* BFS1 */
#define SUPER_BLOCK_MAGIC2 0xdd121031
#define SUPER_BLOCK_MAGIC3 0x15b6830e
超级块中的第一个实际信息是文件系统的块大小。BFS 以两种方式存储块大小。第一种是 block_size 字段,它是一个明确的字节数。因为 BFS 要求块大小是 2 的幂,所以存储将块号转换为字节地址所需的移位位数也很方便。我们为此使用 block_shift 字段。存储两种形式的块大小可以在挂载文件系统时提供额外的检查级别:在有效的文件系统中,block_size 和 block_shift 字段必须一致。
接下来的两个字段,num_blocks 和 used_blocks,记录了此卷上可用的块数以及当前正在使用的块数。这些值的类型是 off_t,在 BeOS 上是 64 位整数。off_t 并非必须是 64 位,实际上 BFS 的早期开发版本仅为 32 位,因为当时编译器不支持 64 位数据类型。num_blocks 和 block_size 字段准确地告诉您磁盘有多大。将它们相乘的结果是文件系统可用的确切字节数。used_blocks 字段记录文件系统当前正在使用的块数。此信息并非绝对必要,但维护起来比每次想知道磁盘有多满时都去计算位图中所有置位(为 1 的位)的总和要方便得多。
下一个字段 inode_size 告诉我们每个 i-node(即文件控制块)的大小。与大多数 Unix 文件系统不同,BFS 不使用预分配的 i-node 表。相反,BFS 按需分配 i-node,并且每个 i-node 至少占用一个磁盘块。这看起来可能过多,但正如我们稍后将描述的那样,事实证明它并没有像你最初想象的那样浪费那么多空间。BFS 主要在为空闲节点分配空间时使用 inode_size 字段,但它也在其他一些情况下用作一致性检查(i-node 大小必须是文件系统块大小的倍数,并且 i-node 本身会存储其大小,以便可以与超级块中的 inode_size 字段进行验证)。
除了超级块中记录的这些信息外,分配组没有与之关联的实际数据结构。超级块的 blocks_per_ag 字段指的是每个分配组中的位图块数。由于上述原因,每个分配组的位图块数映射的块数不得超过 65,536 个。与 block_shift 字段类似,ag_shift 字段记录了在将块运行地址转换为字节偏移量(反之亦然)时对分配组号进行移位的位数。num_ags 字段是此文件系统中的分配组数,用于控制和检查块运行结构的分配组字段。
flags 字段记录超级块的状态:是干净 (clean) 还是脏 (dirty)?
因为 BFS 是日志文件系统,所以它总是以 BFS_CLEAN (0x434c454e) 的值写入超级块。在内存中,在修改磁盘的事务期间,该字段设置为 BFS_DIRTY (0x44495254)。挂载时会检查 flags 字段以验证文件系统是否干净。
关于日志的信息是我们在超级块中找到的下一块信息。日志(在第 7 章中深入描述)是记录对文件系统即将进行的更改的区域。就超级块而言,日志只是一个连续的磁盘块数组。因此,超级块主要需要记录一个块运行数据结构,该结构描述构成日志的磁盘区域。为了维护日志的状态以及我们在其中的位置(因为日志是一个循环缓冲区),我们还在变量 log_start 和 log_end 中维护指向日志开始和结束的指针。
超级块结构的最后两个成员,root_dir 和 indices,将超级块与卷上存储的所有数据连接起来。根目录 i-node 的地址是将超级块连接到卷上所有文件和目录层次结构根的连接点。索引目录 i-node 的地址将超级块与卷上存储的索引连接起来。
没有这两条信息,BFS 将无法找到磁盘上的任何文件。正如我们稍后将看到的,拥有磁盘上 i-node 的地址使我们能够获取该 i-node 的内容(无论它是目录还是文件)。i-node 地址只是一个 len 字段为 1 的块运行结构。
当文件系统处于活动使用状态时,超级块会加载到内存中。内存中有一个 bfs_info 结构,它包含超级块的副本、用于访问底层设备的文件描述符、信号量以及有关文件系统的其他状态信息。bfs_info 结构存储访问卷上所有其他内容所需的数据。
4.6 I-Node 结构 (The I-Node Structure)
当用户打开一个文件时,他们使用人类可读的名称打开它。该名称是一个字符串,易于人们处理。与该名称关联的是一个 i-node 号,这便于文件系统处理。在 BFS 中,文件的 i-node 号是 i-node 数据结构在磁盘上存储位置的地址。文件的 i-node 对于访问该文件的内容(即读取或写入文件等)至关重要。
i-node 数据结构维护有关存在于文件系统中的实体的元信息。i-node 必须记录诸如文件大小、所有者、创建时间、最后修改时间以及有关文件的各种其他信息。i-node 中最重要的信息是关于属于此 i-node 的数据在磁盘上存在位置的信息。也就是说,i-node 是将您连接到文件中数据的连接点。这种基本结构是在文件系统中如何在文件中存储数据的基础构建块。BFS i-node 结构如下:
typedef struct bfs_inode {
int32 magic1; // 魔数1
inode_addr inode_num; // i-node 号(即其在磁盘上的地址)
int32 uid; // 用户ID
int32 gid; // 组ID
int32 mode; // 文件模式(权限和类型)
int32 flags; // 标志
bigtime_t create_time; // 创建时间
bigtime_t last_modified_time; // 最后修改时间
inode_addr parent; // 父目录 i-node 地址
inode_addr attributes; // 属性目录 i-node 地址
uint32 type; // 类型(用于属性)
int32 inode_size; // i-node 大小
binode_etc *etc; // 指向内存中额外信息的指针(磁盘上为NULL)
data_stream data; // 数据流
int32 pad[4]; // 填充字节
int32 small_data[1]; // 小数据区(用于非常小的文件或符号链接)
} bfs_inode;
我们再次看到使用魔数进行一致性检查。i-node 的魔数是 0x3bbe0ad9。如果需要,魔数也可以用于识别不同版本的 i-node。例如,如果将来有必要添加或更改 i-node,新格式的 i-node 可以使用不同的魔数来标识自己。
我们还将此 i-node 的 i-node 号存储在其自身内部,这样就可以很容易地简单地维护一个指向内存中磁盘块的指针,并且仍然记住它在磁盘上的来源。此外,inode_num 字段提供了另一个一致性检查点。
uid/gid 字段是维护文件所有权信息的简单方法。这些字段与 POSIX 风格的 uid/gid 字段非常相似(只是它们是 32 位大小)。
mode 字段存储文件访问权限信息以及有关文件是常规文件还是目录的信息。BFS 中的文件权限模型非常严格地遵循 POSIX 1003.1 规范。也就是说,存在用户、组和“其他”对文件系统实体的访问概念。三种权限类型是读取、写入和执行。这是一种非常简单的权限检查模型(并且它具有相应简单的实现)。
管理所有权信息的另一种方法是通过访问控制列表 (ACL)。ACL 具有许多优点,但在完成 BFS 的可用时间内实现 ACL 被认为是不合理的。ACL 存储有关哪些用户可以访问文件系统项目的显式信息。这比标准的 POSIX 权限模型精细得多;事实上,它们是获得某些形式的美国政府安全认证(例如,C2 级安全)所必需的。也许可以使用文件属性(稍后讨论)来实现 ACL,但该途径尚未被探索。
与往常一样,flags 字段对于记录 i-node 的各种状态信息非常有用。BFS 需要了解有关 i-node 的几件事,其中一些是永久记录的,另一些仅在内存中使用时才使用。BFS 当前理解的标志是:
#define INODE_IN_USE 0x00000001 // I-node 正在使用
#define ATTR_INODE 0x00000004 // 这是一个属性 i-node
#define INODE_LOGGED 0x00000008 // I-node 的数据流被记录日志
#define INODE_DELETED 0x00000010 // I-node 已被删除
#define PERMANENT_FLAGS 0x0000ffff // 永久标志掩码
#define INODE_NO_CACHE 0x00010000 // 不缓存此 i-node (仅内存)
#define INODE_WAS_WRITTEN 0x00020000 // I-node 已被写入 (仅内存)
#define NO_TRANSACTION 0x00040000 // 不为此 i-node 启动事务 (仅内存)
所有活动的 i-node 始终设置 INODE_IN_USE 标志。如果 i-node 引用属性,则设置 ATTR_INODE 标志。ATTR_INODE 标志会影响 BFS 的其他部分如何处理该 i-node。
INODE_LOGGED 标志对 BFS 如何处理 i-node 有很大影响。设置此标志后,写入此 i-node 引用的数据流的所有数据都将被记录日志。也就是说,当此 i-node 的数据流发生修改时,更改将像任何其他日志事务一样被记录日志(有关更多详细信息,请参见第 7 章)。
到目前为止,INODE_LOGGED 标志的唯一用途是用于目录。目录的内容构成文件系统元数据信息——系统正确运行所必需的信息。因为损坏的目录将是灾难性的故障,所以对目录内容的任何更改都必须记录在日志中以防止损坏。
INODE_LOGGED 标志具有潜在的严重影响。记录写入文件的所有数据可能会溢出日志(同样,有关更完整的描述,请参见第 7 章)。因此,唯一设置此标志的 i-node 是目录,其中对数据段执行的 I/O 量可以合理地限制并且受到非常严格的控制。
当用户删除文件时,文件系统会为与该文件对应的 i-node 设置 INODE_DELETED 标志。INODE_DELETED 标志表示不再允许访问该文件。虽然此标志在内存中设置,但 BFS 不会费心将 i-node 写回磁盘,从而在文件删除期间节省了一次额外的磁盘写入。
其余标志仅影响 i-node 加载到内存中时的处理方式。关于 BFS 如何使用这些其他标志的讨论留给它们相关的章节。
回到 i-node 的其余字段,我们找到了 create_time 和 last_modified_time 字段。与 Unix 文件系统不同,BFS 维护文件的创建时间,并且不维护最后访问时间(通常称为 atime)。维护最后访问时间的成本很高,而且通常最后修改时间就足够了。维护最后访问时间的性能成本(即每次接触文件时都进行一次磁盘写入)对于它获得的少量用途来说实在太高了。
为了提高时间字段索引的效率,BFS 将它们存储为 bigtime_t,这是一个 64 位整数。存储的值是一个普通的 POSIX time_t 值左移 16 位,并与一个小计数器进行逻辑或运算。这种操作的目的是帮助创建唯一的时间值,以避免时间索引中不必要的重复(有关更多详细信息,请参见第 5 章)。
下一个字段 parent 是指回包含此文件的目录的引用。该字段的存在与 Unix 风格的文件系统不同。BFS 需要 parent 字段来支持从 i-node 重建完整路径名。在处理查询(在第 5 章中描述)时,需要从 i-node 重建完整路径名。
下一个字段 attributes 可能是 BFS 中 i-node 最不传统的部分。字段 attributes 是一个 i-node 地址。它指向的 i-node 是一个包含有关此文件属性的目录。属性目录中的条目是与文件的属性(名称/值对)对应的名称。我们稍后将讨论属性以及此字段的必要性,因为它们需要冗长的解释。
type 字段仅适用于存储属性的 i-node。属性索引要求它们具有类型(整数、字符串、浮点数等),此字段维护该信息。为此字段选择名称 type 可能比它应有的语义包袱更重一些:它绝不是用来存储诸如 Macintosh HFS 的类型和创建者字段之类的信息。BeOS 将有关文件的真实类型信息存储为名为 BEOS:TYPE 的属性中的 MIME 字符串。
inode_size 字段主要是一个健全性检查字段。BFS 的早期开发版本以更有意义的方式使用该字段,但现在它只是在从磁盘加载 i-node 时执行的另一个检查。
etc 字段只是一个指向有关 i-node 的内存信息的指针。它是存储在磁盘上的 i-node 结构的一部分,这样,当我们将文件系统的一个块加载到内存中时,就可以就地使用它,而无需在使用之前调整磁盘上的表示。
4.7 I-Node 的核心:数据流 (The Core of an I-Node: The Data Stream)
I-Node 的目的是将文件与某些物理存储连接起来。I-Node 的 data 成员是 I-Node 的核心部分。data 成员是一个数据流结构,它提供了程序员在对文件进行 I/O 操作时看到的字节流与这些字节在磁盘上实际位置之间的连接。
数据流结构提供了一种将逻辑文件位置(例如字节 5937)映射到磁盘上某个位置的文件系统块的方法。
数据流结构如下:
#define NUM_DIRECT_BLOCKS 12 // 直接块的数量
typedef struct data_stream {
block_run direct[NUM_DIRECT_BLOCKS]; // 直接块运行数组
off_t max_direct_range; // 直接块可映射的最大范围
block_run indirect; // 间接块运行
off_t max_indirect_range; // 间接块可映射的最大范围
block_run double_indirect; // 双重间接块运行
off_t max_double_indirect_range; // 双重间接块可映射的最大范围
off_t size; // 文件大小(字节数)
} data_stream;
看一个简单的例子将有助于理解数据流结构。假设一个文件有 2048 字节的数据。如果文件系统的块大小为 1024 字节,则该文件将需要两个块来映射所有数据。回顾一下块运行 (block run) 数据结构,我们看到它可以映射 65536 个连续块的运行。由于我们只需要两个,这很简单。因此,一个拥有 2048 字节数据的文件可以有一个长度为 2 的块运行,该块运行将映射文件的所有数据。在一个碎片化程度极高的磁盘上,可能需要两个块运行数据结构,每个长度为 1。无论哪种情况,块运行数据结构都适合直接块提供的空间(即 12 个块运行)。
直接块运行结构可能寻址相当大的数据量。在最佳情况下,直接块可以映射 768MB 的空间(12 个块运行 每个块运行 65536 个 1KB 的块)。在最坏情况下,直接块只能映射 12KB 的空间(12 个块 每个块运行 1 个 1KB 的块)。实际上,直接块映射的平均空间量在几百 KB 到几 MB 之间。
大文件(从几十 MB 到数 GB 的巨型文件)几乎肯定需要比 I-Node 中容纳的 12 个块运行数据结构更多的空间。间接 (indirect) 和双重间接 (double indirect) 字段提供了访问比直接块运行结构可寻址的更大数据量的能力。图 4-1 说明了直接块、间接块和双重间接块如何映射构成文件的数据流。标记为“数据”的矩形是构成文件内容的数据块。数据块旁边虚构的块号只是为了表明文件的连续字节不必在磁盘上连续(尽管连续时更可取)。数据流的间接字段是磁盘上一个块的地址,该块的内容是更多指向实际数据块的块地址。双重间接块地址指向一个块,该块包含间接块的块地址(而间接块又包含更多数据块的块地址)。
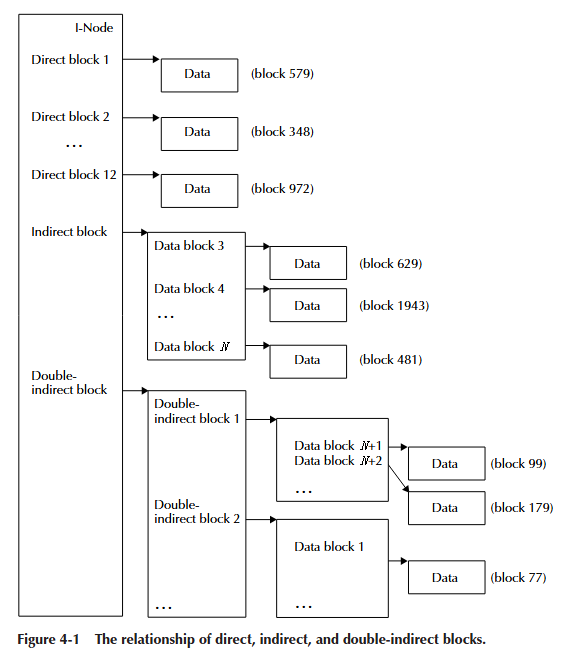
你可能会问,这么多级的间接寻址真的有必要吗?答案是肯定的。事实上,大多数常见的 Unix 风格的文件系统也会有一个三重间接块。BFS 通过使用块运行数据结构避免了三重间接块带来的额外复杂性。BFS 块运行结构可以在一个 8 字节的结构中映射多达 65536 个块。与诸如 Linux ext2 之类的文件系统相比,这节省了大量空间,后者需要 65536 个 4 字节的条目来映射 65536 个块。
那么 BFS 可以寻址的最大文件大小是多少?最大文件大小受多种因素影响,但我们可以针对最佳和最差情况进行计算。在以下计算中,我们将假设文件系统块大小为 1KB。
根据上述数据结构,最坏的情况是每个块运行映射最小量的数据。为了增加最坏情况下映射的数据量,BFS 施加了两个限制。由间接字段引用的块运行大小始终至少为 4KB,因此它可以包含 512 个块运行 (4096/8)。由双重间接块映射的数据块长度也始终至少为 4KB。这有助于避免碎片化并简化查找文件位置的任务(稍后讨论)。
有了这些限制:
直接块 = 12KB (12 个块运行,每个 1KB)
间接块 = 512KB (4KB 的间接块映射 512 个块运行,每个 1KB)
双重间接块 = 1024MB (4KB 的双重间接页映射 512 个间接页,每个间接页映射 512 个块运行,每个块运行 4KB)
因此,最坏情况下的最大文件大小略高于 1GB。我们认为这是可以接受的,因为很难达到这种情况。最坏情况仅在磁盘上每隔一个块都已分配时才会发生。虽然这可能发生,但可能性极小(尽管这是我们常规使用的测试用例)。
最佳情况则大不相同。同样假设文件系统块大小为 1KB:
直接块 = 768MB (12 个块运行,每个 65536KB)
间接块 = 32768MB (4KB 的间接块映射 512 个块运行,每个 65536KB)
双重间接块 = 1GB (4KB 的双重间接页映射 512 个间接页,每个间接页映射 512 个块运行,每个块运行 4KB)
在这种情况下,最大文件大小约为 34GB,这对于当前的磁盘来说是足够的。增加文件系统块大小或每个双重间接块运行映射的数据量将显著增加最大文件大小,为可预见的未来提供足够的增长空间。
了解了数据流结构如何映射文件块之后,我们现在可以回答诸如逻辑文件位置(如字节 37934)如何映射到磁盘上的特定块的问题。让我们从一个简单的例子开始。假设文件的数据流有四个直接块运行结构,每个结构映射 16KB 的数据。该数组如下所示:
direct[0] = { 12, 219, 16 }
direct[1] = { 15, 1854, 16 }
direct[2] = { 23, 962, 16 }
direct[3] = { 39, 57, 16 }
direct[4] = { 0, 0, 0 }
要查找位置 37934,我们将遍历每个直接块,直到找到覆盖我们感兴趣位置的块运行。用伪代码表示如下:
pos = 37934;
for (i=0, sum=0; i < NUM_DIRECT_BLOCKS;
sum += direct[i].len * block_size, i++) {
if (pos >= sum && pos < sum + (direct[i].len * block_size))
break;
}
用文字描述该算法如下:遍历每个块运行结构,直到我们想要的位置大于或等于此块运行的起始位置,并且我们想要的位置小于此当前块运行的结束位置。上述循环退出后,索引变量 i 将引用覆盖所需位置的块运行。使用上面给出的直接块运行数组和位置 37934,我们将在索引等于 2 时退出循环。这将是块运行 16。也就是说,从分配组 23 中的块 962 开始,有一个 16 个块的运行。我们想要的位置 (37934) 在该块运行中,偏移量为 5166 (37934 - 32768)。
随着文件的增长并开始填充间接块,我们将通过加载间接块并以类似于搜索直接块的方式搜索它们来继续上述搜索。因为直接块和间接块中的每个块运行可以映射文件数据的可变数量,所以我们必须始终对它们进行线性搜索。
双重间接块的数量可能非常庞大,这使得像处理直接块和间接块那样线性搜索它们是不可行的。为了缓解这个问题,BFS 总是以固定长度的块运行(当前为四个)来分配双重间接块。通过固定每个双重间接块映射的块数,我们消除了线性迭代所有块的需要。在双重间接块中查找文件位置的问题简化为一系列除法(移位)和模运算。
4.8 属性 (Attributes)
BFS 的一个关键组成部分是它能够将文件的属性与文件一同存储。属性是一个名称/值对。也就是说,PhoneNum = 415-555-1212 是一个属性,其名称是 PhoneNum,其值是 415-555-1212。向文件添加属性的能力提供了大量的可能性。属性允许用户和程序员将关于文件的元信息与文件一起存储,但不在文件数据中。诸如 Keywords、From、Type、Version、URL 和 Icon 之类的属性是人们可能希望存储的关于文件但不必存储在文件本身中的信息类型的示例。
在 BFS 中,一个文件可以有任意数量的与之关联的属性。属性的值部分可以是整数类型(int32、int64、float、double 或字符串),也可以是任意大小的原始数据。如果属性是整数类型,那么如果需要,BFS 可以索引该属性值,以便通过查询接口(在第 5 章中深入描述)进行高效检索。
BeOS 利用属性来存储各种信息。电子邮件守护进程使用属性来存储有关电子邮件的信息。电子邮件守护进程还要求索引这些属性,以便使用查询接口(例如,桌面上的查找面板)我们可以查找和显示电子邮件。文本编辑器支持样式编辑(不同的字体、颜色等),但它没有为文本发明另一种文件格式,而是将样式运行信息存储为属性,而未受损的文本则存储在文件的常规数据流中(因此,例如,允许编辑多字体源代码)。当然,系统上的所有文件都有一个类型属性,以便轻松地将操作给定 MIME 类型的程序与该类型的文件匹配起来。
通过对属性是什么以及如何使用它们的粗略描述,我们现在可以看看实现方式。BFS 将与文件关联的属性列表存储在一个属性目录中(bfs_inode 结构的 attributes 字段)。该目录不是普通目录层次结构的一部分,而是“挂在”文件的一侧。属性目录的命名条目指向相应的属性值。图 4-2 显示了这种关系。
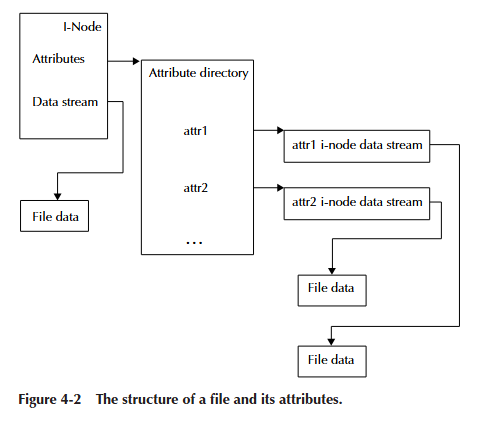
这种结构有一个很好的特性。它重用了几个数据结构:属性列表只是一个目录,而各个属性实际上只是文件。这种重用大大简化了实现。这种设计的一个主要缺陷是,在拥有多个小属性的常见情况下,它也相当慢。
要理解为什么以这种方式存储所有属性太慢,我们必须了解 BFS 运行的环境。BeOS 的主要界面是图形化的——窗口和图标,所有这些都有位置、大小、当前位置等等。用户界面代理(Tracker)将所有这些信息存储为文件和目录的属性。假设用户打开一个包含 10 个项目的目录,并且 Tracker 每个项目有一个属性,那么加载所有信息可能需要多达 30 次不同的寻道操作:每个文件一次以加载 i-node,每个文件的每个属性目录一次,以及每个文件的属性一次。磁盘所能做的最慢的事情就是必须寻道到新位置,而 30 次磁盘寻道很容易导致用户在打开即使只有 10 个文件的小目录时也能察觉到延迟。
需要非常高效地访问合理数量的小属性是 BFS 选择将其每个 i-node 存储在其自己的磁盘块中的主要原因。i-node 结构仅占用略多于 200 字节的空间,这为存储小属性留下了相当大的可用空间。BFS 使用 i-node 磁盘块的空闲区域来存储小属性。这个区域被称为小数据区 (small data area),包含一个紧密打包的可变大小属性数组。大约有 760 字节的空间——足以存储 Tracker 所需的所有信息以及电子邮件守护进程所需的所有信息(它存储九个不同的属性),并且仍然为其他附加属性留下大约 200 字节。这样做带来的性能提升是显著的。现在,通过一次磁盘寻道和读取,我们立即获得了在图形界面中显示项目所需的所有信息。
小数据区的结构如下:
typedef struct small_data {
uint32 type; // 属性类型
uint16 name_size; // 属性名称长度
uint16 data_size; // 属性数据长度
char name[1]; // 属性名称(可变长度)
} small_data;
BFS 将第一个 small_data 结构直接放在 bfs_inode 结构的末尾之后。名称的字节从 name 字段开始并从那里继续。属性值(其数据)紧跟在名称的字节之后存储。为了最大限度地节省空间,没有进行填充以对齐结构(尽管如果 BeOS 必须在具有比 PPC 或 x86 更严格对齐限制的处理器上运行,我可能会后悔这个决定)。小数据区一直持续到包含 i-node 的块的末尾。最后一个区域始终是可用空间(除非可用空间的数量小于 small_data 结构的大小)。
所有文件都有一个隐藏属性,其中包含此 i-node 引用的文件的名称。BFS 将 i-node 的名称存储为一个隐藏属性,该属性始终位于 i-node 的小数据区中。BFS 必须将文件名存储在 i-node 中,以便在仅给定 i-node 的情况下重建文件的完整路径名。正如我们稍后将看到的,从 i-node 到完整路径名的能力对于查询是必需的。
小数据区的引入大大复杂化了属性的管理。所有属性操作必须首先检查属性是否存在于小数据区中,如果不存在,则在属性目录中查找。属性可以存在于小数据区或属性目录中,但绝不能同时存在于两个地方。尽管小数据区增加了复杂性,但性能优势使得这些努力是值得的。
4.9 目录 (Directories)
目录赋予了分层文件系统其结构:目录将用户看到的名称映射到文件系统操作的 i-node 号。目录条目中包含的 i-node 号可以引用文件或其他目录。正如我们在检查超级块时看到的那样,超级块必须包含根目录的 i-node 地址。根目录 i-node 允许我们访问根目录的内容,从而遍历文件系统层次结构的其余部分。
将名称映射到 i-node 号是目录的主要功能,并且有许多方案可以维护这种映射。传统的 Unix 风格的文件系统将目录的条目(名称/i-node 对)存储在一个简单的线性列表中,作为目录数据流的一部分。这种方案实现起来非常简单;然而,当目录中有大量文件时,它的效率并不高。平均而言,您必须读取目录大小的一半左右才能找到给定的文件。这对于少量文件(少于几百个)来说效果很好,但随着文件数量的增加,性能会显著下降。
另一种维护名称/i-node 号映射的方法是使用更复杂的数据结构,例如 B 树。B 树以平衡树结构存储键/值对。对于目录,键是名称,值是 i-node 地址。B 树最吸引人的特性是它们提供 log(n) 的搜索时间来定位项目。将目录条目存储在 B 树中可以加快查找项目所需的时间。因为查找项目以定位其 i-node 所需的时间可能是打开文件总时间的重要组成部分,所以使该过程尽可能高效非常重要。
使用 B+ 树存储目录是 BFS 最具吸引力的选择。目录查找的速度提升是一个不错的好处,但不是做出此决定的主要原因。更重要的是,BFS 还需要一种用于索引属性的数据结构,并且为索引和目录重用相同的 B+ 树数据结构简化了 BFS 的实现。
4.10 索引 (Indexing)
如前所述,BFS 还维护属性值的索引。如果用户和程序员希望对特定属性运行查询,则可以创建索引。例如,邮件守护进程创建名为 From、To 和 Subject 的索引,对应于电子邮件的字段。然后,对于每封到达的邮件(存储在单独的文件中),邮件守护进程会向该文件添加对应邮件 From、To 和 Subject 字段的属性。然后文件系统确保每个属性的值都被索引。
继续这个例子,如果一封电子邮件到达,其 From 字段为 pike@research.att.com,邮件守护进程会向包含该邮件的文件添加一个名为 From 且值为 pike@research.att.com 的属性。BFS 看到属性名 From 是被索引的,因此它将该属性的值 (pike@research.att.com) 和文件的 i-node 地址添加到 From 索引中。
From 索引的内容是所有文件中所有 From 属性的值。该索引使得可以定位具有特定 From 字段的所有电子邮件,或者遍历所有 From 属性。在所有情况下,文件的位置都无关紧要:索引存储文件的 i-node 地址,该地址与其位置无关。
BFS 还维护所有文件的名称、大小和最后修改时间的索引。这些索引使得可以轻松地提出诸如 size > 50MB 或 last modified since yesterday 之类的查询,而无需遍历所有文件来确定哪些文件匹配。
为了维护这些索引,BFS 使用 B+ 树。目录和 B+ 树之间有很多相似之处;事实上,相似之处如此之多,以至于它们几乎无法区分。索引的基本要求是将属性值映射到 i-node 号。如果属性值是字符串,则索引与目录相同。BFS 中的 B+ 树例程支持索引整数(32 位和 64 位)、浮点数、双精度浮点数和可变长度字符串。在所有情况下,与键关联的数据都是 i-node 地址。
BFS 允许任意数量的索引,这就带来了如何存储所有索引列表的问题。文件系统已经为文件解决了这个问题(一个目录可以有任意数量的文件),因此我们选择将可用索引的列表存储为一个“隐藏”目录。除了根目录的 i-node 地址外,超级块还包含索引目录的 i-node 地址。索引目录中的每个名称都对应一个索引,并且与每个名称一起存储的 i-node 号指向该索引的 i-node(请记住,索引和目录是相同的)。
4.11 总结 (Summary)
你在本章中看到的结构定义并非凭空产生,它们也与我开始时使用的结构不同。这些结构是在项目过程中随着我对不同大小和组织的试验而演变的。通过运行基准测试以深入了解各种选择的性能影响,最终形成了你在本章中看到的设计。
I-node 结构在开发过程中经历了多次更改。I-node 最初是一个较小的 256 字节结构,每个文件系统块包含多个 i-node。与当前的 i-node 大小(一个文件系统块)相比,256 字节的大小显得微不足道。最初的 i-node 没有用于存储小属性的小数据区概念(这严重影响了性能)。此外,空闲 i-node 的管理成为系统中的一个重要瓶颈。BFS 不预分配 i-node;因此,必须分块分配 i-node 意味着还必须有一个空闲列表(因为一个磁盘块中可能只有一个 i-node 是空闲的)。该空闲 i-node 列表的管理迫使对超级块(存储列表头部)进行许多更新,并且在文件删除时还需要接触额外的磁盘块。将每个 i-node 更改为其自己的磁盘块为小数据区提供了空间,并简化了空闲 i-node 的管理(释放磁盘块就是所需的全部操作)。
默认的文件系统块大小也经历了几次更改。最初我试验了 512 字节的块,但发现限制太大。512 字节的块大小没有为小数据区提供足够的空间,也与 B+ 树例程不太匹配。B+ 树例程也有页面大小的概念(尽管它与文件系统的其余部分完全独立)。B+ 树例程有一个限制,即存储项的最大大小必须小于 B+ 树页面大小的一半。由于 BFS 允许 255 个字符的文件名,因此 B+ 树页面大小也必须至少为 1024 字节。将最小文件系统块大小推至 1024 字节可确保 i-node 有足够的空间来存储合理数量的属性,并且 B+ 树页面与文件系统块良好对应,这样代表 B+ 树进行的分配和 I/O 操作就不需要任何额外的处理。
你可能会问,如果 1024 字节是一个好的文件系统块大小,为什么不跳到 2048 字节呢?我确实试验了 2048 字节和 4096 字节的块。可用于属性的额外空间并不经常使用(一封电子邮件平均使用约 500 字节存储九个属性)。B+ 树也出现了一个问题,因为它们的尺寸随着 2048 字节的页面大小而显著增长:平衡的 B+ 树往往是半满的,因此平均而言,B+ 树的每个页面只有 1024 字节的有用数据。一些快速实验表明,使用 2048 字节的页面大小,目录和索引的大小增长得比期望的要大得多。结论是,尽管较大的块大小对于非常大的文件具有理想的特性,但对于普通文件而言,增加的成本并不值得。
分配组的概念也经历了相当大的修改。最初的意图是每个分配组允许在文件系统中并行执行操作;也就是说,每个分配组都将显示为一个迷你文件系统。尽管这仍然非常有吸引力(并且事实证明与 Linux ext2 文件系统的工作方式非常相似),但现实是日志记录迫使所有文件系统修改都序列化。每个分配组可能有多个日志;然而,由于时间不足,这个想法没有被采纳。
分配组概念的最初意图是非常大的分配组(大约每 GB 八个)。然而,由于多种原因,这被证明是行不通的:首先也是最重要的是,块运行数据结构只有一个 16 位的起始块号,而且,如此少量的分配组并没有将磁盘分割成足够多的块。取而代之的是,分配组的数量是映射 65536 个块所需的位图块数量的一个因子。通过这种方式确定分配组的大小,我们可以最大限度地利用块运行数据结构。
很明显,许多因素影响着关于文件系统数据结构的大小、布局和组织的设计决策。尽管决策可能基于直觉,但通过查看几种替代方案的性能来验证这些决策是否合理非常重要。
本章对构成 BFS 的原始数据结构的介绍为理解构成完整文件系统的更高级别概念奠定了基础。