第 6 章 - 分配策略 (Allocation Policies)
6.1 你把东西放在磁盘的什么位置?(Where Do You Put Things on Disk?)
Be文件系统将磁盘视为一个块数组。这些块从零开始编号,一直到设备的 最大磁盘块。从文件系统的角度来看,这种存储设备视图简单且易于操作。 但物理磁盘的几何结构不仅仅是简单的磁盘块数组。文件系统用来安排数据 在磁盘上位置的策略,会对文件系统的整体性能产生重大影响。本章解释了 什么是分配策略、如何在磁盘上安排数据的不同方式,以及利用磁盘物理特性 提高文件系统吞吐量的其他机制。
6.2 什么是分配策略?(What Are Allocation Policies?)
分配策略是文件系统用于决定将项目放置在磁盘何处的规则和启发法集合。 分配策略决定了文件系统元数据(i-node、目录数据和索引)以及文件数据的 位置。用于此任务的规则从简单到复杂不等。幸运的是,一套规则的有效性并 不总是与复杂性相匹配。
分配策略的目标是安排数据在磁盘上的布局,以便在以后检索数据时提供 尽可能最佳的吞吐量。有几个因素影响分配策略的成功。定义良好分配策略 的一个关键因素是了解磁盘如何运作。了解磁盘擅长什么以及哪些操作成本 更高,有助于构建分配策略。
6.3 物理磁盘 (Physical Disks)
物理磁盘是一个复杂的机械装置,包含许多部分(参见第3章的图3-1)。 出于我们讨论的目的,我们只需要了解磁盘的三个部分:盘片、磁道和磁头。 每个磁盘都由一组盘片组成。盘片薄、圆形且呈金属状。现代磁盘使用直径 在2-5英寸之间的盘片。盘片有两面,每一面都划分成磁道。磁道是围绕盘片 的窄圆形环。任何特定的磁道与盘片中心的距离总是相同的。每个盘片每面 通常有2000到5000个磁道。每个磁道又划分成扇区(或磁盘块)。扇区是 磁盘驱动器可以读取或写入的最小不可分割单位。一个扇区通常大小为512字节。
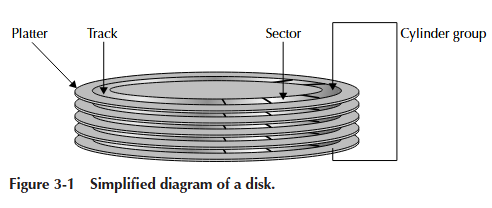
每个盘片有两个磁头,一个用于上面,一个用于下面。所有磁头都连接在 同一个磁臂上,并且所有磁头都对齐。通常,每个磁头下的所有磁道被统称为 一个柱面或柱面组。所有磁头同时访问每个盘片上的同一磁道。虽然这很有趣, 但某些磁头读取一个磁道而其他磁头读取不同磁道是不可能的。
在同一个柱面内执行I/O非常快,因为它几乎不需要磁头移动。在同一个柱面内 从一个磁头切换到另一个磁头比重新定位到不同的磁道要快得多,因为只需要 对磁头位置进行微小调整即可从不同磁头上的同一磁道读取数据。
从一个磁道移动到另一个磁道涉及到所谓的寻道。跨磁道寻道需要磁臂在 磁盘上的物理移动,从一个位置到另一个位置。将磁臂重新定位到新磁道需要 将新位置的精度控制在0.05-0.1毫米以内。找到位置后,磁臂和磁头必须稳定下来 才能进行I/O。寻道中移动的距离也会影响完成寻道所需的时间。寻道到相邻磁道 所需的时间少于从最内层磁道寻道到最外层磁道所需的时间。在进行I/O之前, 从一个磁道寻道到另一个磁道所需的时间称为寻道时间。寻道时间通常为5-20毫秒。 这可能是现代计算机系统中最慢的操作。
尽管前面几段讨论了磁盘驱动器非常底层的几何结构,但大多数现代磁盘 驱动器都竭力向用户隐藏这些信息。即使操作系统提取了物理几何信息,驱动器 也很可能为了自身的需求而伪造了信息。磁盘驱动器这样做是为了能够以对 特定驱动器最优化方式将逻辑磁盘块地址映射到物理位置。在磁盘驱动器内部 执行映射允许制造商利用对驱动器的深入了解;如果宿主系统试图利用驱动器的 物理知识来优化访问模式,它只能以一种通用的方式进行。
尽管磁盘驱动器在隐藏物理几何结构方面做了很多工作,但理解不同类型 操作所涉及的延迟问题会影响文件系统分配策略的设计。构建分配策略时另一个 重要考虑因素是了解磁盘擅长什么。任何磁盘能执行的最快操作是读取连续的 数据块。顺序I/O之所以快,是因为它最容易实现快速。对大型连续内存块的I/O 允许操作系统利用DMA(直接内存访问)和突发总线传输。此外,在磁盘驱动器 层面,大型传输利用了任何板载缓存,并允许驱动器充分利用其块重映射功能, 从而减少将数据传输到/从盘片所需的时间。
一个简单的测试程序有助于说明一些相关问题。测试程序打开一个裸设备, 生成一个随机的块地址列表(1024个),然后计时读取该随机列表的块所需的时间, 与将它们按排序顺序读取所需的时间进行比较。在BeOS系统上使用几种不同的 磁盘驱动器(Quantum、Seagate等)时,我们发现按排序顺序读取1024个块与 按随机顺序读取所需的时间差接近两倍。也就是说,仅仅对块列表进行排序就 将读取所有块所需的时间从16秒减少到大约8.5秒。为了说明随机I/O和顺序I/O 之间的差异,我们还让程序通过一次读取操作读取相同总量的数据(512K)。 该操作花费了不到0.2秒完成。尽管绝对数字会因测试使用的硬件配置而异,但 这些数字的重要性在于它们之间的相对关系。差异是惊人的:大型连续数据块 的顺序I/O比甚至排序的I/O列表快近50倍,比纯随机顺序读取相同量的数据快近100倍。
从这些数据中可以得出两个重要的结论:连续I/O是磁盘可以执行的最快操作, 至少快一个数量级。了解顺序I/O和随机I/O之间速度的巨大差异,我们可以看到, 以牺牲数据局部性为代价来试图紧凑数据结构是没有意义的。读取一个大型连续 数据结构要快得多,即使它的大小是更紧凑但分散的数据结构的10倍。这相当反直觉。
另一个显著的结论是,当I/O必须在许多不同位置进行时,批量处理多个事务 是明智的。通过将操作批量处理并对生成的块地址列表进行排序后再执行I/O, 文件系统可以利用不同操作之间的任何局部性,并将磁盘寻道成本分摊到许多 操作上。这种技术可以将执行I/O所需的时间减半。
6.4 你可以布局哪些内容?(What Can You Lay Out?)
定义分配策略的第一步是决定策略将影响哪些文件系统结构。在BFS中, 主要有三种需要布局决策的结构:
- 文件数据
- 目录数据
- i-node数据
首先,文件数据的分配策略将对文件系统如何有效利用磁盘带宽产生最大影响。 一个好的文件数据分配策略会尝试保持文件数据连续。如果文件数据不连续 或分散在磁盘各处,文件系统将永远无法发出足够大的请求来利用实际的磁盘速度。
衡量文件数据分配策略的有效性很简单:比较对文件进行I/O的最大带宽 与以原始方式访问设备的最大带宽。带宽差异表明了文件数据分配策略引入的 开销。最小化文件系统在对文件进行I/O时的开销非常重要。理想情况下,文件 系统应该引入尽可能少的开销。
下一个可控制的项目是目录数据。尽管目录将其内容存储在常规文件中, 但我们将目录数据与普通文件数据分开,因为目录包含文件系统元数据。文件 系统元数据的存储具有与常规用户数据不同的约束。当然,保持目录数据的 连续分配很重要,但还有另一个因素需要考虑:目录对应的i-node存储在哪里? 强制磁臂进行大范围移动以便从目录条目转到必要的i-node可能会对性能产生 灾难性影响。i-node数据的位置很重要,因为所有对文件的访问都必须首先加载 所引用文件的i-node。i-node的组织和位置与目录数据面临同样的问题。将目录 数据和文件i-node放置在彼此附近可以极大地提升速度,因为当需要一个时, 另一个通常也需要。通常,所有i-node都存在于磁盘上的一个固定区域,因此 分配策略在某种程度上变得无关紧要。当i-node可以存在于磁盘的任何位置时 (如BFS),分配策略就更加重要了。
衡量目录数据和i-node分配策略有效性有几种不同的方法。最简单的方法是 测量在一个目录中创建不同数量文件所需的时间。这是一种粗略的测量技术, 但能很好地指示文件创建和删除中的开销。另一种技术是测量遍历目录内容 (可以选择同时检索每个文件的信息,即stat())所需的时间。
在较小程度上,块位图和日志区域的位置也会影响性能。块位图在为文件 分配空间时会频繁写入。选择块位图的良好位置可以避免过长的磁盘寻道。 日志文件系统的日志区域也涉及大量的I/O。同样,选择日志区域的良好位置 可以避免长时间的磁盘寻道。
文件系统分配策略能够控制的项目数量很少。分配策略主要控制的项目是 文件数据。关于文件系统元数据(如目录数据块和i-node)的分配策略在各种 操作的速度中也起着重要作用。
6.5 访问类型 (Types of Access)
文件系统的不同访问类型会根据分配策略表现不同。某种访问类型在某种 分配策略下可能表现不佳,而另一种访问模式可能表现极好。此外,一些分配 策略可能会在空间与时间之间进行权衡,这并不适用于所有情况。
文件系统执行的有趣且值得优化的操作类型有:
- 打开一个文件
- 创建一个文件
- 向文件写入数据
- 删除一个文件
- 重命名一个文件
- 列出目录内容
在这个操作列表中,我们必须选择哪些进行优化,哪些忽略。提高某个操作 的速度可能会降低另一个操作的速度,或者某个操作的理想策略可能与其它 操作的目标冲突。
打开一个文件包含许多操作。首先,文件系统必须检查目录,查看是否包含 我们想要打开的文件。在目录中搜索名称是一个目录查找操作,可能需要进行 暴力搜索或其他更智能的算法。如果文件存在,我们必须加载关联的i-node。
在理想情况下,分配策略会放置目录和i-node数据,以便可以通过一次磁盘 读取同时读取它们。如果文件系统只需要完美地安排数据,这将是一项容易的 任务。在现实世界中,文件会不断创建和删除,维持目录和i-node数据之间的完美 关系非常困难。一些文件系统直接将i-node嵌入目录中,这确实保持了这种关系, 但代价是增加了文件系统其他部分的复杂性。一般来说,将目录数据和i-node 放置在彼此附近是一件好事。
创建一个文件会修改几个数据结构——至少包括块位图和目录,以及可能需要 维护的任何索引。分配策略必须为新文件选择一个i-node和在目录中的位置。 在一个干净的磁盘上选择i-node的好位置很容易,但更常见的情况是在磁盘上 创建和删除大量文件后选择i-node。
向文件写入数据的分配策略面临许多相互冲突的目标。小文件不应该浪费磁盘空间, 将它们紧密打包有助于避免碎片化。大文件应该连续存放,并避免构成文件的块地址 出现大的跳跃。这些目标经常冲突,并且通常无法知道最终会写入文件多少数据。
当用户删除文件时,文件系统会释放与文件关联的空间。删除文件留下的空洞 可以进行紧凑处理,但这会带来显著的困难,因为文件系统必须移动数据。移动数据 可能会导致无法接受的性能延迟。理想情况下,文件系统会在创建下一个文件时重用 之前文件留下的空洞。
重命名文件通常不是时间关键操作,因此受到的关注较少。重命名过程中主要修改的 数据结构是目录数据,如果文件系统上存在名称索引,也会修改它。由于在大多数系统中, 重命名操作不那么频繁,因此重命名操作涉及的I/O不足以值得花费大量时间进行优化。
列出目录内容的速度直接受到分配策略及其在磁盘上安排数据效率的影响。如果目录 内容紧跟着i-node数据,预取将通过一次连续I/O带来大量相关数据块。这种布局在空文件 系统上很容易确保,但在文件经常被删除和重新创建的正常使用情况下很难维持。
应用于这些操作的分配策略将影响文件系统的整体性能。根据文件系统的预期目标, 可以就如何以及在何处放置文件系统结构做出各种选择。如果追求极致的紧凑性, 删除移除文件留下的空洞可能是有意义的。或者,忽略空洞并在创建新文件时填充它 可能更有效。权衡这些冲突的目标并决定适当的解决方案是文件系统分配策略的范畴。
6.6 BFS 中的分配策略 (Allocation Policies in BFS)
现在让我们看看 BFS 选择的分配策略。
分配组:底层组织 (Allocation Groups: The Underlying Organization)
为了帮助管理磁盘空间,BFS引入了一个称为分配组的概念。分配组是一种 软结构,因为它在磁盘上没有对应的实际数据结构。分配组是一种为了分配 策略目的而将组成文件系统的块划分为块的方式。
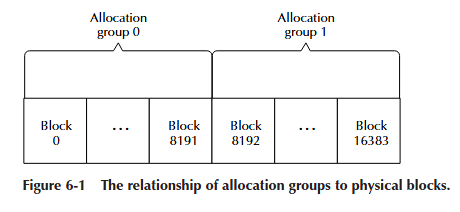
在 BFS 中,一个分配组是至少包含 8192 个文件系统块的集合。分配组边界 位于磁盘块位图的块大小块上。也就是说,一个分配组总是至少是文件系统 块位图的一个块。如果文件系统的块大小为 1024 字节(BFS 首选和允许的 最小大小),那么一个位图块将包含多达 8192 个不同块的状态(一个块中的 1024 字节乘以 8,即 1 字节中的位数)。非常大的磁盘每个分配组可能包含 多个位图块。
如果一个文件系统有 16,384 个 1024 字节的块,位图将是两个块长(2 * 8192)。 这足以构成两个分配组,如图 6-1 所示。
分配组是一个概念上的辅助工具,用于帮助决定将各种文件系统数据结构 放在何处。通过将磁盘划分为固定大小的块,我们可以安排数据,使得相关 项目彼此靠近。放置规则仅仅是规则,这意味着它们是可以被打破的。用于 指导数据结构放置的启发法并不严格。如果磁盘空间紧张或磁盘非常碎片化, 为了任何目的使用任何磁盘块都是可以接受的。
尽管分配组是一种软结构,但适当的大小设置会影响整个文件系统性能的 几个因素。通常,一个分配组只有 8192 个块长(即,一个位图块)。因此, 一个块运行的最大大小为 8192 个块,因为一个块运行不能跨越一个以上的 分配组。如果一个块运行只能映射 8192 个块,这将限制文件的大小。假设 分配完美(即每个块运行都被完全分配),一个文件可以存储的最大数据量 约为 5 GB:
12 个直接块运行 = 96 MB(每个块运行 8192K)
512 个间接块运行 = 4 GB(512 个块运行,每个 8192K)
256,000 个双间接块运行 = 1 GB(256K 个块运行,每个 4K)
映射的总数据 = 5.09 GB
在小于 5 GB 的驱动器上,这样的文件大小限制不是问题,但在更大的驱动器上, 这就变得更加棘手。解决方案非常简单。增加每个分配组的大小会增加每个 块运行可以映射的数据量,最大可达每个块运行 64K 块。如果每个分配组是 65,536 个块长,则最大文件大小将超过 33 GB:
12 个直接块运行 = 768 MB(每个块运行 64 MB)
512 个间接块运行 = 32 GB(512 个块运行,每个 64 MB)
256,000 个双间接块运行 = 1 GB(256K 个块运行,每个 4K)
映射的总数据 = 33.76 GB
双间接块映射的空间也可以通过将每个块运行映射 8K 或更多(而不是 4K)来增加。 当然,增加文件系统块大小也会增加最大文件大小。如果需要更大的文件大小, BFS 还具有一个未使用的三间接块,这将使文件大小增加到约 520 GB。
创建文件系统时,BFS 会选择分配组的大小,使得最大文件大小大于设备的大小。 为什么文件系统不总是将分配组设置为 65,536 个块长?因为在较小的卷上,如此 大的分配组会导致所有数据都落入一个分配组,从而违背了将目录数据和 i-node 与文件数据分开聚类的目的。
目录和索引分配策略 (Directory and Index Allocation Policy)
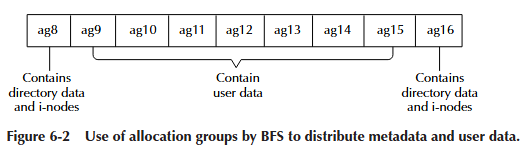
BFS 保留前八个分配组作为索引及其数据的首选区域。BFS 保留这八个分配组 仅仅是约定俗成;没有什么能阻止 i-node 或文件数据块被分配到磁盘的这个区域。 如果磁盘变满,BFS 会根据需要使用前八个分配组中的磁盘块。将索引隔离到 前八个分配组,为它们提供了至少 64 MB 的磁盘空间用于增长,并防止文件 数据或普通目录数据与索引数据混杂在一起。这种方法的优点是索引倾向于缓慢 增长,这使得它们有空间增长而不会被普通文件数据碎片化。
所有 BFS 文件系统的根目录都始于第八个分配组(即从块 65,536 开始)。 除非磁盘非常大,否则根目录 i-node 通常是 i-node 号 65,536。当磁盘非常大 (即大于 5 GB)时,每个分配组包含的块更多,根目录 i-node 块会被推得更远。
一个目录的所有数据块都从与目录 i-node 相同的分配组中分配(如果可能)。 文件 i-node 也被放在包含它们的目录的同一分配组中。结果是目录数据和目录中 文件的 i-node 块将彼此靠近。子目录的 i-node 块被放置在再往后八个分配组的地方。 这有助于将数据分散到整个驱动器上,以免过多数据集中在一个分配组中。文件 数据被放置在包含目录和 i-node 数据之外的分配组中。也就是说,每第八个分配组 主要包含目录数据和 i-node 数据;中间的七个分配组包含用户数据(参见图 6-2)。
文件数据分配策略 (File Data Allocation Policy)
在 BFS 中,文件数据的分配策略努力确保文件尽可能连续。第一步是在文件 首次写入或增长时预分配空间。如果写入文件的数据量小于 64K 并且文件 需要增长以容纳新数据,BFS 会为文件预分配 64K 的空间。BFS 选择 64K 的 预分配大小有几个原因。由于大多数文件的大小小于 64K,通过预分配 64K, 我们几乎可以保证大多数文件是连续的。另一个原因是,对于大于 64K 的文件, 每次分配 64K 的连续块允许文件系统对连续的磁盘块执行大型 I/O。64K 的大小 (根据经验)足够大,使得磁盘能够以接近其最大带宽传输数据。预分配还有 另一个好处:它将文件增长的成本分摊到更大的 I/O 量上。由于 BFS 是日志文件 系统,文件增长需要启动新的事务。如果每次写入几字节数据就必须启动新的 事务,文件写入性能将因事务成本而受到负面影响。预分配确保了大多数文件 数据是连续的,同时通过每次数据增长只增长 64K 而不是每次 I/O 都增长, 从而降低了文件增长的成本。
预分配确实有一些缺点。文件实际大小很少正好是 64K,因此文件系统必须 在某个时候修剪未使用的预分配空间。对于常规文件,文件系统在文件关闭时 修剪任何未使用的预分配空间。修剪预分配空间是另一个事务,但它没有我们 想象的那么昂贵,因为在文件关闭时,为了维护大小和最后修改时间索引, 已经需要另一个事务。修剪文件未使用的空间也会修改与分配期间修改的位图 块相同的位图块,因此 BFS 很容易将对文件的多次修改合并到单个日志事务中, 这进一步降低了成本。
预分配和文件连续性的风险 (Dangers of Preallocation and File Contiguity)
BFS 努力确保文件数据在磁盘上连续,并且在磁盘没有严重碎片化的常见情况下 做得相当好。但并非所有磁盘都能保持未碎片化,在某些退化情况下,预分配以及 文件系统尝试分配连续磁盘块的行为可能会导致非常糟糕的性能。在 BFS 开发 过程中,我们发现运行磁盘碎片整理程序会在系统下次重启时造成混乱。启动时, 虚拟内存系统会要求创建一个相当大的交换文件,BFS 会尝试尽可能连续地创建它。 算法会花费大量时间搜索文件中尝试分配的每个块的连续块运行。搜索会遍历整个 位图,直到发现最大连续空闲块运行约为 4K 左右,然后停止。这个过程在适中 大小的磁盘上可能需要几分钟。
由此得到的教训是,文件系统需要对其分配策略保持智能。如果文件系统在尝试 分配大型连续运行块时失败次数过多,文件系统应该切换策略,只需尝试分配任何 可用的块。BFS 使用了这种技术以及块位图中的一些提示,以便它能够“知道” 磁盘何时非常满,从而文件系统应该切换策略。知道磁盘何时不再满也很重要, 以免文件系统只在一个方向上切换策略。幸运的是,这些类型的策略决策易于修改 和调整,并且不影响磁盘上的结构。这使得以后可以调整文件系统而不会影响 现有结构。
预分配和目录 (Preallocation and Directories)
目录为预分配策略带来了有趣的困境。目录的大小会增长,但通常比文件增长慢得多。 当向目录中添加更多文件时,目录的大小会增长,但与文件不同的是,目录没有真正 的“打开”和“关闭”操作(即,无需先打开目录即可在其内部创建文件)。这使得何时 应修剪目录中预分配的块不太明确。当目录 i-node 从内存中刷新时,BFS 会修剪目录 数据。这种修剪预分配数据的方法有几个优点。目录数据的预分配允许目录增长并 保持连续。通过延迟修剪数据直到不再需要目录,文件系统可以确保目录的所有内容 都是连续的,并且近期不太可能再次增长。
6.7 总结 (Summary)
本章讨论了选择在磁盘上放置数据结构所涉及的问题。硬盘的物理特性在 分配策略中起着重要作用。文件系统分配策略的最终目标是连续布局数据结构, 并尽量减少磁盘寻道。文件系统选择放置 i-node、目录数据和文件数据的位置 可以显著影响文件系统的整体性能。