第 9 章 - 文件系统性能 (File System Performance)
衡量和分析文件系统性能是编写文件系统的一个重要组成部分。如果没有一些衡量文件系统实现的指标,就没有办法评估其质量。我们可以通过其他一些指标来判断文件系统——例如,可靠性——但我们假设,在考虑性能之前,可靠性必须是前提。衡量性能对于理解应用程序的表现以及文件系统能够处理的工作负载类型很有用。
9.1 什么是性能?(What Is Performance?)
文件系统的性能有许多不同的方面。衡量文件系统的性能有许多不同的方法,这是一个活跃的研究领域。事实上,甚至没有一个与 CPU 的 SPEC 基准测试相对应的常用磁盘基准测试。不幸的是,似乎每当一个新的文件系统被编写出来,新的基准测试也会随之被编写出来。这使得比较文件系统变得非常困难。
有三个主要的文件系统衡量类别是值得关注的:
- 吞吐量基准测试(每秒兆字节的数据传输量)
- 元数据密集型基准测试(每秒操作数)
- 真实世界工作负载(吞吐量或每秒事务数)
吞吐量基准测试衡量文件系统在各种条件下每秒可以提供多少兆字节的数据传输量。最简单的情况是文件的顺序读写。使用多线程、不同文件大小和文件数量也可以进行更复杂的吞吐量测量。吞吐量测量非常依赖于所使用的磁盘,因此,绝对测量虽然有用,但在不同系统之间进行比较很困难,除非使用相同的硬盘。一个更有用的衡量标准是文件系统达到的原始磁盘带宽的百分比。也就是说,直接对磁盘设备执行大的顺序 I/O 会产生一定的数据传输速率。将文件系统顺序 I/O 的吞吐量作为原始磁盘带宽的百分比来衡量,可以得到一个更容易比较的数字,因为这个百分比实际上是一个归一化数字。传输速率非常接近原始驱动器传输速率的文件系统是理想的。
元数据密集型基准测试衡量文件系统每秒可以执行的操作数量。文件系统执行的主要元数据密集型操作是打开、创建、删除和重命名。在这些操作中,重命名通常不被视为性能瓶颈,因此很少被关注。其他操作会显著影响使用文件系统的应用程序的性能。每秒的操作数越高,文件系统的性能越好。
真实世界基准测试利用文件系统来执行一些任务,例如处理电子邮件或互联网新闻、从存档中提取文件、编译大型软件系统或复制文件。除了文件系统本身之外,许多不同的因素会影响真实世界基准测试的结果。例如,如果虚拟内存系统和磁盘缓冲区缓存集成在一起,系统可以更有效地利用内存作为磁盘缓存,从而提高性能。尽管统一的 VM 和缓冲区缓存可以提高大多数与磁盘相关的测试的性能,但这与文件系统的质量(或不足)无关。尽管如此,真实世界基准测试很好地表明了一个系统执行特定任务的能力。关注真实世界任务的性能很重要,这样系统才不会被优化成只运行特定的合成基准测试。
9.2 哪些是基准测试?(What Are the Benchmarks?)
有大量的的文件系统基准测试可用,但我们偏向于测量文件系统性能特定领域的简单基准测试。简单的基准测试易于理解和分析。在 BFS 的开发过程中,我们只使用了少数基准测试。使用的两个主要测试是 IOZone 和 lat_fs。
IOZone 由 Bill Norcott 编写,是一个直接的吞吐量测量测试。IOZone 使用命令行上指定的 I/O 块大小顺序写入文件,然后顺序读回文件。文件的大小也在命令行上指定。通过调整 I/O 块大小和总文件大小,可以轻松调整 IOZone 的行为,以反映许多不同类型的顺序文件 I/O。幸运的是,顺序 I/O 是程序执行的主要 I/O 类型。此外,我们预计 BeOS 将用于向磁盘传输大量数据(以大型音频和视频文件的形式),因此 IOZone 是一个很好的测试。
第二个测试 lat_fs 是 Larry McVoy 的 lmbench 测试套件的一部分。lat_fs 首先创建 1000 个文件,然后删除它们。lat_fs 测试对文件大小为 0 字节、1K、4K 和 10K 的文件执行此操作。基准测试的结果是文件系统对于每种文件大小每秒可以创建和删除的文件数量。尽管它极其简单,但 lat_fs 测试是一种衡量文件系统最重要的两个元数据密集型操作的直接方法。lat_fs 测试的唯一缺点是它只创建固定数量的文件。为了观察更大数量文件的行为,我们编写了一个类似的程序,在一个目录中创建和删除任意数量的文件。
除了使用这两个测量外,我们还运行了几个真实世界的测试,试图客观地了解文件系统在常见任务中的速度。第一个真实世界测试只是简单地计时大型(10-20 MB)存档的打包和解包。这很好地衡量了文件系统处理实际文件大小(而不是所有文件大小固定)时的表现,并且数据集足够大,不会完全放入缓存中。
第二个真实世界测试只是编译一个源代码库。它不一定是磁盘密集度最高的操作,但由于许多源代码文件都很小,它们会花费大量时间打开许多头文件,因此涉及相当数量的文件系统操作。当然,我们在选择这个基准测试时确实有一些偏见,因为提高它的速度直接影响我们的日常工作(包括编译大量代码)!
其他真实世界测试仅仅是运行涉及大量磁盘 I/O 的实际应用程序并观察它们的性能。例如,一个在 BeOS 上运行的面向对象数据库软件包有一个基准测试模式,可以计时各种操作。视频捕获等其他应用程序也很好地作为应用程序行为的真实示例。并非所有真实世界测试都能得出具体的性能数字,但它们能否成功运行直接衡量了文件系统的质量。
其他基准测试 (Other Benchmarks)
如前所述,还有相当多的其他文件系统基准测试程序。最值得注意的是:
- Andrew 文件系统基准测试 (Andrew File System Benchmark)
- Bonnie
- IOStone
- SPEC SFS
- Chen 的自适应缩放基准测试 (Chen’s self-scaling benchmark)
- PostMark
前三个基准测试(Andrew、Bonnie 和 IOStone)不再是特别有趣的基准测试,因为它们通常完全适合文件系统缓冲区缓存。Andrew 基准测试的工作集很小,主要由编译大量源代码构成。尽管我们认为编译代码是一个有用的衡量标准,但如果 Andrew 基准测试只能告诉我们这些,那么投入精力移植它几乎不值得。
Bonnie 和 IOStone 的工作集非常小,很容易适合大多数文件系统缓冲区缓存。这意味着 Bonnie 和 IOStone 最终测量的是从缓冲区缓存到用户空间的 memcpy() 速度——这是一个有用的测量,但与文件系统关系不大。
SPEC SFS 基准测试(以前称为 LADDIS)旨在测量网络文件系统(NFS)服务器的性能。这是一个有趣的基准测试,但您必须是 SPEC 组织的成员才能获得它。此外,由于它旨在测试 NFS,因此需要 NFS 和多个客户端。SPEC SFS 基准测试并非真正针对独立的 文件系统,也不是一个容易运行的基准测试。
Chen 的自适应缩放基准测试解决了 Andrew、Bonnie 和 IOStone 基准测试中存在的一些问题。通过调整基准测试参数以适应被测系统,该基准测试能更好地适应不同的系统,并避免了静态大小的参数最终变得过小的问题。基准测试的自适应缩放使得无法在不同系统之间比较结果。为了解决这个问题,Chen 使用“预测性能”来计算一个可以与其他系统比较的系统性能曲线。不幸的是,预测性能曲线仅以每秒兆字节表示,对于指示系统哪些领域需要改进作用不大。Chen 的自适应缩放基准测试是一个很好的通用测试,但对于我们的需求来说不够具体。
最近加入基准测试阵营的是 PostMark。PostMark 测试由 Network Appliance(一家 NFS 服务器制造商)编写,试图模拟大型电子邮件系统的工作负载。该测试创建一组初始工作文件,然后执行一系列事务。这些事务包括读取文件、创建新文件、向现有文件追加数据和删除文件。测试的所有参数都可以配置(文件数量、事务数量、读/写数据量、读/写百分比等)。这个基准测试会得出三个性能数字:每秒事务数、有效读取带宽和有效写入带宽。默认参数使得 PostMark 成为一个非常好的小文件基准测试。通过调整参数,PostMark 可以模拟各种工作负载。PostMark 的另外两个关键特性是源代码可以免费下载,并且可以移植到 Windows 95 和 Windows NT。能够移植到 Windows 95 和 Windows NT 非常重要,因为这两个操作系统很少受到专注于 Unix 的研究社区的关注。很少有(如果有的话)其他基准测试可以在 POSIX 和 Win32 API 下不经修改地运行。能够在各种系统(不仅仅是 Unix 衍生系统)之间直接比较 PostMark 的性能数字很有用。遗憾的是,PostMark 于 1997 年 8 月才发布,因此对 BFS 的设计没有产生影响。
基准测试的危险 (Dangers of Benchmarks)
运行任何一套基准测试的最大陷阱是它会迅速演变成一场在特定基准测试上击败所有其他文件系统的竞赛。除非所讨论的基准测试是重要客户应用程序的真实世界测试,否则为特定基准测试优化文件系统不太可能有助于提高整体性能。事实上,很可能发生恰恰相反的情况。
在 BFS 的开发过程中,有一段时间,lat_fs 基准测试成为了性能改进的唯一重点。通过各种技巧,lat_fs 的性能得到了显著提高。不幸的是,同样的更改却降低了其他更常见的操作的速度(例如解压文件存档)。这显然不是理想的情况。
基准测试的危险在于,很容易只关注一个性能指标。除非这个指标是唯一关注的指标,否则只关注一个基准测试很少是一个好主意。运行各种测试,特别是真实世界的测试,是防止进行仅适用于单个基准测试的优化的最佳保护。
运行基准测试 (Running Benchmarks)
文件系统的基准测试几乎总是在新创建的文件系统上运行。这确保了最佳性能,这也意味着基准测试数字可能有点误导。然而,很难准确地“老化”文件系统,因为没有标准化的方法来老化文件系统,使其看起来像经过一段时间使用后那样。尽管不能呈现全貌,但在干净的文件系统上运行基准测试是比较文件系统性能数字的最安全方式。
通过在运行基准测试之前,让系统进行一组明确定义的文件系统活动,可以获得更完整的文件系统性能图景。这是一项困难的任务,因为任何特定的文件系统活动集很可能只代表一种工作负载。由于准确地老化文件系统并针对各种工作负载进行操作存在困难,因此通常不这样做。这并不是说老化文件系统不可能,但除非准确、可重复且一致地完成,否则报告老化文件系统的文件系统基准测试将是不准确且具有误导性的。
9.3 性能数字 (Performance Numbers)
尽管基准测试存在种种注意事项,但硬性数字是无可替代的。这些测试的目标不是为了证明某个文件系统的优越性,而是为了提供一个总体概况,说明每个文件系统在不同测试中的表现。
测试设置 (Test Setup)
对于 BeOS、Windows NT 和 Linux 的测试,我们的测试配置是一台双处理器 Pentium Pro 机器。主板是 Tyan Titan Pro (v3.03 10/31/96),带有 Award Bios。主板使用 Intel 440FX 芯片组。我们将机器配置为 32 MB RAM。测试中使用的磁盘是 IBM DeskStar 3.2 GB 硬盘 (型号 DAQA-33240)。机器还配备了 Matrox Millennium 显卡和 DEC 21014 以太网卡。所有操作系统都使用同一块物理硬盘上的同一分区进行测试(以消除从内层柱面或外层柱面读取的差异)。
对于 BeOS 测试,我们从生产 CD-ROM 安装了适用于 Intel 的 BeOS Release 3,配置了图形(1024 x 768 分辨率,16 位颜色)和网络(TCP/IP)。我们没有安装其他软件。在具有 32 MB 系统内存的系统上,BeOS 使用固定的 4 MB 内存作为磁盘缓存。
对于 Windows NT 测试,我们安装了带有 Service Pack 3 的 Windows NT Workstation 4.00 版。我们进行了标准安装,没有选择任何特殊选项。与 BeOS 安装一样,我们配置了图形和网络,没有安装其他软件。使用任务管理器,我们观察到在我们的测试配置上,Windows NT 使用了多达 20-22 MB 的内存作为磁盘缓存。
Linux ext2 测试使用了 RedHat 4.2 Linux 发行版的副本,该版本基于 Linux v2.0.30 内核。我们进行了标准安装,并在文本模式下从控制台运行所有测试。系统使用了大约 28 MB 的内存作为缓冲区缓存(通过运行 top 并在运行基准测试时观察缓冲区缓存统计信息来测量)。
对于 XFS 测试,我们在 Onyx2 系统上使用了 Irix 6.5 的晚期 Beta 版本。Onyx2 在物理上与 Origin-2000 相同,但配备了图形板。该机器有两个 250 MHz R10000 处理器和 128 MB RAM。磁盘是一块 IBM 93G3048 4 GB Fast & Wide SCSI 磁盘,连接到 Onyx2 内置的 SCSI 控制器。Irix 使用了总系统内存的很大一部分作为磁盘缓存,尽管我们无法确定具体使用了多少。
为了获得下表中的数字,我们对所有测试运行了三次并取平均值。每次测试集开始前都初始化了所有文件系统,以最大限度地减少其他测试对结果的影响。我们在测试期间尽量保持所有系统处于静止状态,以便只测量文件系统性能以外的因素。
流式 I/O 基准测试 (Streaming I/O Benchmark)
IOZone 基准测试测量系统将顺序数据块写入文件的速度。这对 BeOS 来说是一个有趣的测试,因为它的预期用途之一是向磁盘传输和接收大量媒体数据。这个测试不测量密集的文件系统元数据操作。
IOZone 基准测试有两个参数:总的读/写数据量和每次 I/O 操作的块大小。运行 IOZone 的结果是读写数据的带宽(以每秒兆字节为单位)。IOZone 报告的绝对数字只有适度的兴趣,因为它们取决于磁盘控制器和所使用的磁盘的细节。
与其关注 IOZone 报告的绝对数字,不如测量文件系统与访问底层原始设备磁盘相比引入了多少开销。首先测量原始设备带宽,然后将其与通过文件系统写入实现的带宽进行比较,可以了解文件系统和操作系统引入了多少开销。
为了测量原始设备带宽,在 BeOS 下我们使用了 IOZone 对原始磁盘设备进行测试(没有文件系统,只是对磁盘进行原始访问)。在 Windows NT 下,我们运行了一个专门测量原始磁盘带宽的程序,并观察到几乎相同的结果。对于前面描述的测试配置,表 9-1 显示了结果。

IOZone 测试的所有百分比都是相对于这些绝对带宽数字给出的。重要的是要注意,这些是超过 128 MB 数据的持续传输速率。这个速率与通常引用的驱动器“峰值传输速率”不同,后者通常是通过重复读取磁盘上的同一数据块来测量的。
我们使用三组不同的参数运行了 IOZone。我们选择足够大的文件大小,以减少磁盘缓存(如果存在)的影响。我们选择大的 I/O 块大小来模拟向磁盘传输大量数据。表 9-2 到表 9-4 显示了结果。



在这些测试中,BFS 表现异常出色,因为它绕过了系统缓存并直接对用户缓冲区进行 DMA。在 BeOS 下,测试期间的处理器利用率低于 10%。在 NT 下的相同测试使用了 20-40% 的 CPU;如果在测试期间发生任何其他操作(例如,在桌面上单击鼠标),测试结果会因为大量的页面交换而急剧下降。Linux ext2 的表现令人惊讶地好,尽管它通过缓冲区缓存传递数据。原因之一是磁盘的速度(约 6 MB/秒)明显低于机器的 memcpy() 带宽(约 50 MB/秒)。如果磁盘子系统更快,Linux 相对于磁盘最大速度的表现就不会那么好了。BeOS 的直接 I/O 方法在这种情况下表现出色,并且能够适应更高性能的磁盘子系统。
文件创建/删除基准测试 (File Creation/Deletion Benchmark)
Larry McVoy 和 Carl Staelin 的 lmbench 测试套件是一个广泛的基准测试套件,涵盖了性能的许多领域。该套件中的一个测试 lat_fs,测试文件系统上创建和删除操作的速度。尽管它是高度合成的,但该基准测试提供了一个衡量文件创建和删除成本的简单标尺。
我们使用前面描述的系统进行这些测试。我们还在关闭索引的情况下在创建的 BFS 卷上运行了基准测试。观察索引和非索引 BFS 之间的速度差异可以了解维护默认索引(名称、大小和最后修改时间)的成本。非索引 BFS 的情况与 NTFS 和 XFS 进行比较也更公平,因为它们不索引任何东西。
我们使用了来自原始 lmbench 测试套件的 lat_fs v1.6(而不是 lmbench 2.0),因为它更容易移植到 NT。lat_fs 测试创建 1000 个文件(向每个文件写入固定量的数据),然后返回并删除所有文件。测试迭代四次,每次增加写入的数据量。每次迭代写入的数据量为 0K、1K、4K,然后是 10K。测试的结果是文件系统对于给定文件大小每秒可以创建或删除的文件数量(参见表 9-5 和表 9-6)。
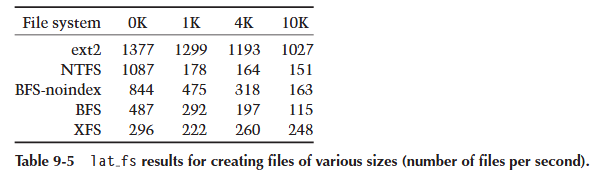
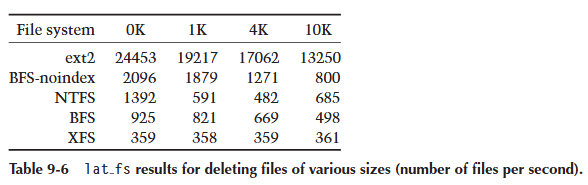
这个测试的结果需要仔细审查。首先,Linux ext2 的数字几乎毫无意义,因为在这些基准测试期间,ext2 文件系统一次都没有触及磁盘。ext2 文件系统(如第 3.2 节所述)不提供一致性保证,因此在内存中执行所有操作。在 Linux 系统上运行 lat_fs 基准测试仅仅测试用户程序进入内核、执行 memcpy() 并退出内核的速度。我们不认为 ext2 的数字有意义,除非作为文件系统在内存中运行速度的上限。其次,很明显 NTFS 对处理创建 0 字节文件进行了特殊优化,因为在这种情况下结果与其他 NTFS 结果完全不一致。当写入的数据量开始超出 BeOS 可怜的 4 MB 磁盘缓存时,BFS 的性能会显著下降。BFS 受限于缺乏统一的虚拟内存和磁盘缓冲区缓存。
总体而言,非索引 BFS 表现良好,在除两种情况外的所有情况下都取得了最高分。XFS 和 NTFS 文件创建性能相对稳定,很可能是因为所有写入的文件数据都适合它们的磁盘缓存,并且它们的性能受到写入日志速度的限制。从这个测试得出的一个结论是,BFS 将受益于一个更好的磁盘缓存。
从表 9-5 和表 9-6 中,我们还可以推断出 BFS 卷上索引的成本。默认情况下,BFS 会索引所有文件的名称、大小和最后修改时间。在所有情况下,非索引 BFS 的速度几乎是常规 BFS 的两倍。对于某些环境,索引的成本可能不值得增加的功能。
PostMark 基准测试 (The PostMark Benchmark)
PostMark 基准测试由 Network Appliance (www.netapp.com) 的 Jeffrey Katcher 编写,是对电子邮件或 NetNews 系统的模拟。这个基准测试对文件系统元数据密集度极高。尽管有许多参数,我们只修改了两个参数:初始文件基础数量和对文件集执行的事务数量。测试首先创建指定数量的基础文件,然后迭代该文件集,随机选择操作(创建、追加和删除)来执行。PostMark 使用自己的随机数生成器,并且默认使用相同的种子,这意味着测试总是执行相同的工作,并且不同系统的结果是可以比较的。
对于每个测试,读写的数据总量以绝对数字(兆字节)给出。然而,这个数字有点误导,因为同一数据可能被多次读取,有些文件可能在数据写入磁盘之前就被写入和删除了。因此,尽管读写的数据量看起来可能显著大于缓冲区缓存,但事实可能并非如此。
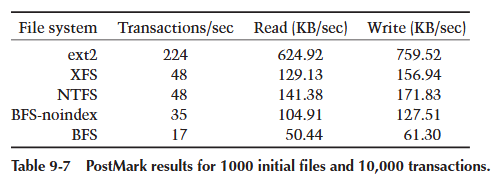
第一次测试从 1000 个初始文件开始,并在这些文件上执行 10,000 个事务。这次测试写入了 37.18 MB 数据,读取了 30.59 MB。结果(如表 9-7 所示)并不令人惊讶。Linux ext2 的结果异常高,表明测试的大部分内容都适合其缓存。正如我们将看到的那样,一旦数据量开始超出其缓存大小,ext2 的性能数字就会急剧下降。
普通 BFS(即带有索引的)表现出可怜的每秒 17 个事务,原因有几个:索引的成本很高,并且触及的数据量很快就超出了缓存。非索引 BFS 的速度大约是两倍(如 lat_fs 结果所预期的那样),尽管它仍然落后于 NTFS 和 XFS。再次,缺乏真正的磁盘缓存对 BFS 不利。
对于下一次测试,我们将初始文件集增加到 5000 个。这次测试总共读取了 28.49 MB 数据,写入了 57.64 MB。结果如表 9-8 所示。这些数据量开始溢出 ext2、NTFS 和 XFS 的缓存,这使得它们的数字有所下降。非索引 BFS 保持了自己的优势,接近 NTFS。常规版本的 BFS 再次表现出非索引版本性能的一半。
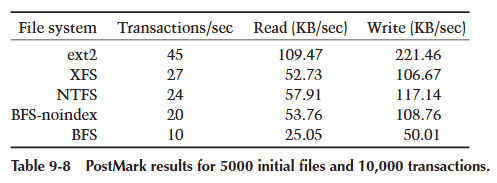
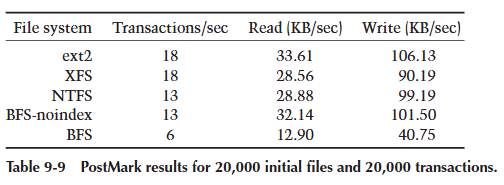
最后一次 PostMark 测试是最残酷的:它创建了 20,000 个初始文件集,并对该文件集执行 20,000 个事务。这次测试读取了 52.76 MB 数据,写入了 166.61 MB。这是一个足以使所有缓存失效的数据量。表 9-9 显示了结果。在这里,所有文件系统都开始下降,每秒事务数下降到可怜的 18 个,即使对于强大的(且不安全的)ext2 也是如此。普通 BFS 的表现是迄今为止最差的,每秒只有 6 个事务。索引 BFS 的这个结果清楚地表明,索引不适合用于高吞吐量的文件服务器。
分析 (Analysis)
总体而言,我们可以从这些性能数字中得出一些结论:
- BFS 在向磁盘传输和接收流式数据方面表现出色。达到高达磁盘可用带宽的 99%,BFS 在文件 I/O 过程中引入的开销非常小。
- 当数据大小大部分适合缓存时,BFS 在元数据更新方面表现良好。正如 0K、1K 和 4K lat_fs 测试所示,BFS 的性能优于除 ext2 文件系统外的所有其他系统(这很公平,因为 ext2 在测试期间从未触及磁盘)。
- 缺乏统一的虚拟内存和缓冲区缓存系统在修改许多小文件中大量数据的基准测试(即 PostMark 基准测试)中显著损害了 BFS 的性能。作为证据,考虑最后一次 PostMark 测试(20,000/20,000 运行)。这次测试写入的数据量足以抵消其他系统中缓存的影响,在这种情况下(非索引)BFS 的表现与其他文件系统差不多。
- BFS 进行的默认索引操作在元数据更新测试中会导致大约 50% 的性能损失,这在 PostMark 基准测试结果中清晰可见。
总而言之,BFS 在其预期用途(流式媒体传输)方面表现良好。对于元数据密集型基准测试,BFS 的表现相当不错,直到索引的成本和缺乏动态缓冲区缓存使其速度下降。对于以事务式处理最重要的系统,禁用索引可以显著提高性能。然而,在 BeOS 提供统一的虚拟内存和缓冲区缓存系统之前,BFS 在高强度事务导向的系统中不会像其他系统那样表现出色。
9.4 BFS 中的性能 (Performance in BFS)
在 BFS 的初步开发阶段,性能并不是主要关注点,实现方式也比较直接。随着其他工程师开始使用文件系统,性能成为了一个更大的问题。这需要仔细检查文件系统在正常操作下的实际行为。事实证明,查看文件系统的 I/O 访问模式是提高性能的最佳方法。
文件创建 (File Creation)
对 BFS 来说,第一个成为问题的“基准测试”是我们每日 BeOS 构建的存档解压性能。使用几天后,BFS 会退化,直到每秒只能解压大约一个文件。这种糟糕的性能是由于检查文件系统的 I/O 日志时非常明显的一些因素造成的。通过在每次磁盘 I/O 执行时插入打印语句,并分析写入的块号和每次 I/O 的大小,很容易看出问题所在。
首先,当时 BFS 每个日志缓冲区只保留一个事务。这导致对磁盘日志的写入次数过多。其次,当缓存刷新数据时,它不会合并连续的写入。这意味着缓存实际上是一次写入一个文件系统块(通常是 1024 字节),从而严重削弱了可用的磁盘带宽。为了缓解这些问题,我扩展了 journaling 代码以支持每个日志缓冲区多个事务。然后修改了缓存代码,以批量刷新块并合并对连续位置的写入。
这两项更改显著提高了性能,但 BFS 仍然感觉有些迟钝。再次检查 I/O 日志,发现了另一个问题。通常一个块在事务中会被修改多次,并且每次修改都会被写入一次。如果一个块是单个日志缓冲区(可能包含多个事务)的一部分,则无需在日志缓冲区中为该块消耗多个副本的空间。这项修改大大减少了日志缓冲区中使用的块数,因为解压文件时通常同一目录块会被修改多次。
缓存 (The Cache)
在检查缓存执行的 I/O 时,很明显地,对即将刷新的磁盘块地址进行简单的排序有助于减少磁盘臂移动,使磁盘臂以一次大的扫描方式运行,而不是随机移动。磁盘寻道是磁盘可以执行的最慢的操作,通过对缓存需要刷新的块列表进行排序来最小化寻道时间可以显著提高性能。
不幸的是,在编写缓存代码时,BeOS 不支持 Scatter/Gather I/O。这使得需要将连续的块复制到临时缓冲区,然后再从临时缓冲区将它们 DMA 到磁盘。这种额外的复制效率低下,并且当 I/O 子系统支持 Scatter/Gather I/O 时最终将变得不必要。
分配策略 (Allocation Policies)
另一个有助于性能的因素是调整分配策略,以便尽可能以最优方式分配文件系统数据结构。当程序顺序创建大量文件时,文件系统有机会以最优方式布局其数据结构。顺序创建文件的最优布局是连续分配 i-node,将它们放置在包含它们的目录附近,并将文件数据连续放置。这样做的好处是预读可以在一次读取中获取许多文件的信息。BFS 最初没有以连续方式分配文件数据。问题在于文件数据块的预分配会在连续文件之间造成间隙。文件的预分配空间直到文件关闭很久之后才会被释放。一旦通过仔细检查文件系统生成的 I/O 模式发现了这个问题,修复它就很容易了(现在在 close() 时修剪预分配的数据块)。
重复测试 (The Duplicate Test)
在 BFS 开发的最后阶段,进行了一些真实世界测试,以查看接近完成版本的 BFS 在同一硬件平台(Mac OS)上与竞争对手的表现如何。令我惊讶的是,Mac OS 在复制包含数百个文件的文件夹时比 BeOS 快得多。尽管 BeOS 必须维护三个索引(名称、大小和最后修改时间),我仍然期望它比 Mac OS 文件系统 HFS 快。理解这个问题再次需要检查磁盘访问模式。磁盘访问模式显示 BFS 大约 30% 的时间花在了更新名称和大小索引上。进一步检查发现,B+tree 数据结构在管理文件名称和大小的重复条目时产生了大量流量。
B+tree 处理重复条目的方式是不可接受的。B+tree 会为每个重复的值分配 1024 字节的文件空间,然后仅在该空间中写入两个不同的 i-node 号码(16 字节)。问题在于,当复制文件层次结构时,每个文件在名称和大小索引中都会成为重复(如果复制保留所有属性,则最后修改时间索引也是如此)。对各种系统上存在的重复文件名数量的额外调查显示,大约 70% 的重复文件名中,同名文件少于八个。这些信息提示了一个显而易见的解决方案。B+tree 代码不再为每个重复项分配一个 1024 字节的块空间,而是可以将这个 1024 字节的块分割成一组片段,每个片段可以容纳少量重复项。在多个重复项之间共享为单个重复项分配的空间,大大减少了所需的 I/O 量,因为每个重复项不再需要写入 B+tree 中自己的区域。另一个有利的影响是减小了磁盘上 B+tree 文件的大小。代价是增加了管理 B+tree 的复杂性。在对 BFS 进行这些修改后,我们重新运行了原始测试,发现 BFS 在复制一组文件夹时与 HFS 一样快或更快,即使 BFS 为所有文件额外维护了三个索引。
日志区域 (The Log Area)
另一个可以进行性能调优的领域是磁盘上的日志区域。日志区域的大小直接影响可能存在的未完成日志事务数量,从而影响磁盘缓冲区缓存的使用效率。如果日志区域很小,则在日志填满之前只能进行少量事务。一旦日志区域满,文件系统必须强制将块刷新到磁盘,以便事务完成并在日志中释放空间。如果日志区域很小,几乎没有任何事务会在内存中缓冲,从而缓存利用不足。增加日志大小可以更好地利用磁盘缓冲区缓存,从而允许更多事务在内存中完成,而不是需要不断刷新到磁盘。BFS 将日志大小从 512K 增加到 2048K,性能显著提升。根据机器中的内存量进一步调优日志区域也许是合适的,但是,日志区域一旦在磁盘上创建,即使计算机中的内存量发生变化,其大小也是固定的。无论如何,至少了解这种行为是值得的。
9.5 总结 (Summary)
许多因素都会影响性能。通常需要仔细关注 I/O 访问模式和磁盘上数据结构布局,以帮助调优文件系统以达到最佳性能。BFS 通过检查文件系统的访问模式并调优数据结构和分配策略来减少 I/O 流量,从而获得了许多改进。